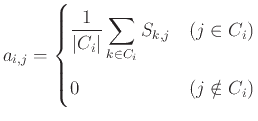TfIdfを重要度とした式(3.13)のような文書行列に、名詞のクラスター分析による次元圧縮を行うことで、クラスターと文書からなるクラスター-文書行列が作成される。このとき、クラスター-文書行列の重要度は、式(3.18)で表されるクラスターと名詞の行列と元の文書行列との積で求められる。
各クラスターを 、単語を とする。 は次の式で与えられる。