


Next: 潜在的意味解析
Up: テキストマイニング
Previous: ベクトル空間法による文書の類似度の算出
目次
日本語Wordnetを用いた文書の類似度の算出
日本語Wordnetとは日本語の意味辞書である。
語を類義関係のセット(synset)でグループ化しており、各synsetは上位下位関係などの多様な関係で結ばれており、
一つのsynsetが一つの概念に対応すると考えられている。
そこで、synsetの上位関係ancestorを用いて語と語の距離を関連度とし、関連度を用いて類似度の計算に反映させる。
日本語Wordnetにおける、二つの単語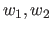 の単語間の関連の略図を図2.3に示す。
図2.3において、
の最も近い共通のancestorまでの距離を
の単語間の関連の略図を図2.3に示す。
図2.3において、
の最も近い共通のancestorまでの距離を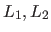 、
一番上位のancestorまでの距離を
、
一番上位のancestorまでの距離を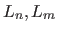 とする。
このとき、
とする。
このとき、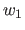 と
と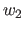 との関連度
との関連度
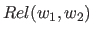 を式(2.7)で表す。
関連度は日本語Wordnet上での単語間の距離が少しでも遠ければ値が0に近くなるよう反比例の関数で設計した。
そうすることで類似度が無駄に増加してしまうことを避けるためである。
を式(2.7)で表す。
関連度は日本語Wordnet上での単語間の距離が少しでも遠ければ値が0に近くなるよう反比例の関数で設計した。
そうすることで類似度が無駄に増加してしまうことを避けるためである。
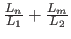 とすることで反比例の関数とし、
とすることで反比例の関数とし、 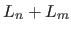 を分母とすることで0〜1に正規化している。
を分母とすることで0〜1に正規化している。
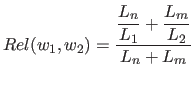 |
(2.7) |
また、文書D,Eの関連度を含めた類似度は式(2.8)で表す。
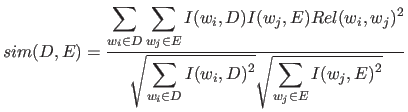 |
(2.8) |
ここで、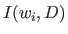 は文書
は文書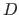 における重要語
における重要語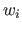 の重要度を表している。
の重要度を表している。
Deguchi Lab.
2012年3月12日
![\includegraphics[scale=0.3]{figure/japanese_wordnet.eps}](img89.png)