


Next: Rでの特異値分解
Up: 潜在的意味解析
Previous: 潜在的意味解析
目次
潜在的意味解析(LSA : Latent Semantic Analysis)は、文書行列を圧縮することで、分類を効果的に行う技術である。
ここでいう文書行列とは、式(2.9)のような重要語と文書の行列である。
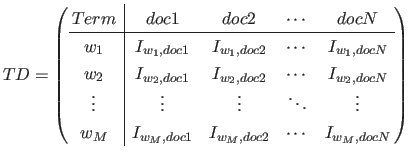 |
(2.9) |
ここで、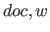 はそれぞれ
はそれぞれ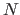 個の文書、
個の文書、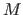 個の重要語を示し、
個の重要語を示し、
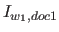 は
は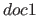 における
における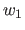 の重要度を表す。
の重要度を表す。
このような文書行列は高次元であるため、分類や検索などの処理を行うには相当量の計算が必要になるのに加え、
次元が増えるにつれて分類の妨げになる単語も増え、これがノイズのように邪魔になることがある。
潜在的意味解析は、高次元の文書行列を低次元で近似的に表現する技術である。
以下に、このLSAの中身について簡単に説明する。
ある文書行列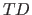 に、次の行列式で表される分解(特異値分解)を行う。
に、次の行列式で表される分解(特異値分解)を行う。
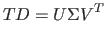 |
(2.10) |
この式で
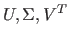 は行列を表す記号であり、右辺は三つの行列の積を表している。
は行列を表す記号であり、右辺は三つの行列の積を表している。
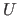 は左特異(ターム)ベクトル、
は左特異(ターム)ベクトル、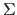 は特異値を含むベクトル、
は特異値を含むベクトル、 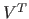 は右特異(文書)ベクトルと呼ばれる。
この分解によって出た左特異ベクトルの列ベクトルは左にあるものほど重要度が高いので、
左から最初の
は右特異(文書)ベクトルと呼ばれる。
この分解によって出た左特異ベクトルの列ベクトルは左にあるものほど重要度が高いので、
左から最初の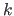 個だけで表される行列を
個だけで表される行列を 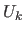 とする。
すると、式(2.11)の行列積を求めることで、もとの文書行列に近似した行列を作成することができる。
とする。
すると、式(2.11)の行列積を求めることで、もとの文書行列に近似した行列を作成することができる。
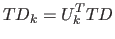 |
(2.11) |
Deguchi Lab.
2012年3月12日