上記の得点![]() は以下の式によって計算される。
は以下の式によって計算される。
ここで![]() は目標距離であり、
は目標距離であり、![]() と
と![]() がどれだけ離れていれば望ましいかを表す。実験ではこの値を2としたので、
がどれだけ離れていれば望ましいかを表す。実験ではこの値を2としたので、![]() が1で
が1で![]() が100に近ければ、多くの教科が一番似ているとされる教科と科目構成図において2つほどしか離れておらず、適切な類似度が求められていることが分かる。
が100に近ければ、多くの教科が一番似ているとされる教科と科目構成図において2つほどしか離れておらず、適切な類似度が求められていることが分かる。
この![]() を用いて、複合語と重要度の有無をそれぞれ切り替えた4つのデータを2値化処理をせずに比較した結果を表4.6に、また、グラフ化したものを図4.1に示す。
を用いて、複合語と重要度の有無をそれぞれ切り替えた4つのデータを2値化処理をせずに比較した結果を表4.6に、また、グラフ化したものを図4.1に示す。
| 抽出 教科数 |
複合語有 | 複合語無 | ||
| 重要度無 | 重要度有 | 重要度無 | 重要度有 | |
| 1 | 35.80 | 32.95 | 31.61 | 32.22 |
| 2 | 32.04 | 31.65 | 30.37 | 31.14 |
| 3 | 31.78 | 31.84 | 30.82 | 31.58 |
| 4 | 32.24 | 33.17 | 30.83 | 31.72 |
| 5 | 31.90 | 32.28 | 30.77 | 32.33 |
また、4つのデータを2値化処理をした後に比較した結果を表4.7に、グラフ化したものを図4.2に示す。
| 抽出 教科数 |
複合語有 | 複合語無 | ||
| 重要度無 | 重要度有 | 重要度無 | 重要度有 | |
| 1 | 35.80 | 32.22 | 31.61 | 32.95 |
| 2 | 32.08 | 31.37 | 31.69 | 31.17 |
| 3 | 32.34 | 30.68 | 31.80 | 32.41 |
| 4 | 32.79 | 32.09 | 31.69 | 33.61 |
| 5 | 32.78 | 32.95 | 32.04 | 33.16 |
実験結果を見ると、各スコアの値は30から36の間の値を取っていることが分かる。
未2値化処理時の結果は表4.6より、複合語に着目すると抽出教科数が多い時、複合語が有効の結果よりも、複合語無効の結果の方がスコアが高くなっていることがわかる。 重要度に着目すると、抽出教科数が多くなるにつれて、重要度を考慮したものの方が結果が良くなっていることが分かる。このことより、多くの比較対象がある時、重要度を考慮した方がよりよい結果が得られると考えられる。また、抽出教科数が少ない時、複合語あり・重要度なしで計算した時の結果が、他のものと比べて良くなっていることがわかる。
2値化処理時の結果は表4.7のようになった。2値化処理をしていない時の結果と比較すると、複合語無し・重要度無しのスコアが未2値化処理時よりも全体的に高くなっていることがわかる。 複合語無し・重要度無しの結果を見ると、他の結果に比べ変化が小さく、スコアも低いことがわかる.
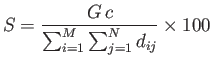
![\includegraphics[scale = 1.0]{dtmno.eps}](img123.png)
![\includegraphics[scale = 1.0]{dtm.eps}](img124.png)