上記の得点![]() は以下の式によって計算される。
は以下の式によって計算される。
ここで![]() は目標距離であり、
は目標距離であり、![]() と
と![]() がどれだけ離れていれば望ましいかを表す。実験ではこの値を2としたので、
がどれだけ離れていれば望ましいかを表す。実験ではこの値を2としたので、![]() が1で
が1で![]() が100に近ければ、多くの教科が一番似ているとされる教科と科目構成図において2つほどしか離れておらず、適切な類似度が求められていることが分かる。
が100に近ければ、多くの教科が一番似ているとされる教科と科目構成図において2つほどしか離れておらず、適切な類似度が求められていることが分かる。
この![]() を用いて4つのデータを比較した結果を表4.6に示す。
を用いて4つのデータを比較した結果を表4.6に示す。
| 編集無 | 編集有 | |||
| 重要度無 | 重要度有 | 重要度無 | ||
| 1 | 37.79 | 38.78 | 40.96 | |
| 2 | 36.27 | 38.20 | 38.27 | 38.20 |
| 3 | 35.31 | 38.25 | 38.01 | 40.05 |
| 4 | 35.16 | 37.71 | 37.16 | 39.80 |
| 5 | 35.11 | 37.75 | 36.77 | 39.84 |
重要度に着目すると、重要度を考慮しなかった時よりも、考慮したときの方が得点が高いことが分かる。この結果から重要度は考慮した方がよいと考えられる。次に、シラバスのテキストファイルに編集しているかどうかに着目してみる。表とグラフから分かるように、前処理をしている方が得点が高いことが分かる。つまり、前処理をした方がより正確な結果が得られるといえる。これは、シラバスをPDF形式からテキストファイルに変化する時にPDF形式のレイアウトのままで行が改行されてしまうことが原因だと考えられる。このとき、一つの単語が改行により分解され別々の単語に分けられてしまうことになる。 今回の実験結果でも1E電気電子設計製図のTermExtractの結果ファイルに「コンピュー」という単語が結果に表示されていた。これは、「コンピュータ」という単語が改行により「コンピュー」と「タ」に分けられたと考えられる。このような現象がほかのシラバスの結果にも見られた。したがって、類似度が下がり得点率が下がっている原因だと言える。
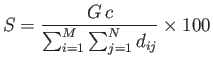
![\includegraphics[scale=1.0]{fig03.eps}](img118.png)