この研究は、ニューラルネットワークに実空間に近いゲームを設定して、 学習と実行を試みる。ゲームは、この研究のために用意したものを使用する。
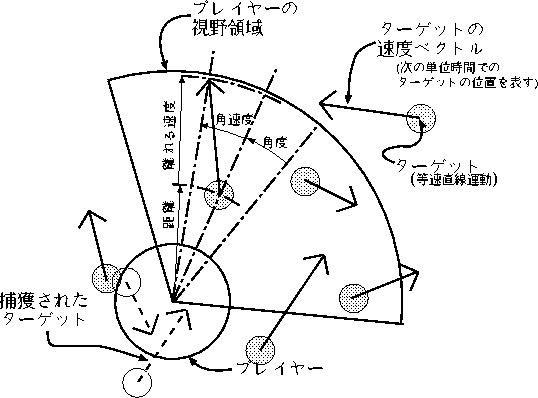
ルールは、正方形のフィールド上を動き回るターゲットを プレーヤーがターゲットと重なることで「捕獲」したこととし これを繰り返し全て捕獲すると終りという単純なもので、 プレーヤーは単位時間ごとに環境からの入力と、それによる出力を繰り返す。 操作は、プログラムやニューラルネットワークを用いる。
プレーヤーの大きさは半径30で、その視野は角度 ![]() [rad]
距離200に限定されている。
ただし、単位距離はコンピュータの
画面上のドットを1とし、単位は[pixel]とする。
プレーヤーには視野の中にあるターゲットの情報が提供され、
それを前処理するなどして
ニューラルネットワークなどに入力することができる。
提供される情報はプレーヤーを中心にした時、ターゲットの
[rad]
距離200に限定されている。
ただし、単位距離はコンピュータの
画面上のドットを1とし、単位は[pixel]とする。
プレーヤーには視野の中にあるターゲットの情報が提供され、
それを前処理するなどして
ニューラルネットワークなどに入力することができる。
提供される情報はプレーヤーを中心にした時、ターゲットの
![]()
とそれぞれ計算する。
ターゲットは、初速での等速直線運動を続け、 フィールドの端まで来ると跳ね返るという動作を繰り返す。 ターゲットに、もう少し変化のついた動作をさせることもできたが、 変化をつけるとプレーヤーへの入力に入りきらない情報も ターゲットの動作の決定を左右することにる。 したがって、与えられた情報だけをたよりに 動作する今回のニューラルネットワークは、 ターゲットに予期せぬ変化があると うまく学習できたか評価できないという 性質上、ターゲットの動作に変化をつけることは 無意味であるのでしなかった。