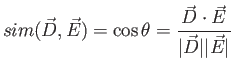前節ではある文書における各単語の重要度を算出した。 次にその重要度を利用して、ベクトル空間法という計算方法を用い、複数の文書同士の類似度を計算する。
ベクトル空間法とは、文書を多次元空間上のベクトルとして表現し、 二つのベクトルを比較することにより類似度を調べるものである。 つまり、ベクトルの方向は文書の特徴であるので、二つのベクトルのなす角が小さいほど似ているということである。
![]() 個のタームを持つ文書
個のタームを持つ文書![]() を形態素解析し、各ターム毎の重要度を
を形態素解析し、各ターム毎の重要度を
![]() としたとき、
文書
としたとき、
文書![]() のベクトルは以下のように表される。
のベクトルは以下のように表される。
これらベクトル ![]() とベクトル
とベクトル ![]() の類似度の計算は以下の式で実現できる。
の類似度の計算は以下の式で実現できる。
以下の例文で実際に類似度の計算を行う。
| 例1 |
| C言語のプログラムを理解できる. |
| C言語の簡単なプログラムを作成できる. |
| 有用なアルゴリズムを理解する. |
| 例2 |
| C言語の簡単なプログラムを作成できる. |
| アルゴリズム(サーチ,ソートなど)を理解できる. |
次に、この例1、例2を形態素解析し、重要度を計算したものを表3.1に示す。
| 用語 | 例文1 | 例文2 |
| C言語 | 3.46 | 1.41 |
| プログラム | 2.00 | 1.00 |
| アルゴリズム | 1.00 | 1.00 |
| サーチ | 1.00 | |
| ソート | 1.00 |
この例1、例2は式(3.16)の形式に表すと
次に、この2つのベクトルの大きさを計算する。
最後に式(3.17)より、この2つの例文の類似度を計算する。
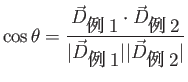 |
|||
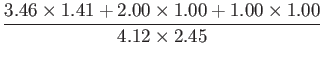 |
|||