


Next: ベクトル空間法
Up: 実験に関する手法
Previous: 主成分分析
目次
潜在的意味解析 [6,8]
3.1 項で述べた、結合係数を特異値分解(Singular Value Decomposition)により求めてデータの縮約を行うのが、この潜在的意味解析(Latent Semantic Analysis:以下LSA)に当たる。情報検索の分野ではLSI(Latent Semantic Indexing)とも言い、ベクトル空間モデルを用いた自然言語処理の1つである。テキストマイニングでは多量のデータを扱う為に、文書も用語の数も多くなる。すると文書と用語のデータ行列は高次元になり、データ全体が表す傾向を把握しにくい。そこでLSAを用いて低次元の近似行列を作り、余分な計算やノイズを除去するのである。以下に、このLSAの中身について説明する。
まず文書が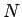 個のデータ行列
個のデータ行列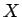 がある時、これを特異値分解すると左特異(ターム)ベクトル
がある時、これを特異値分解すると左特異(ターム)ベクトル
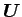 , 右特異(文書)ベクトル
, 右特異(文書)ベクトル
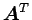 , 個の特異値を含むベクトル
, 個の特異値を含むベクトル
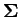 が得られる。
が得られる。
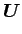 |
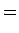 |
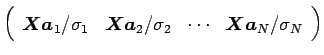 |
(3.9) |
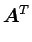 |
|
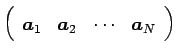 |
(3.10) |
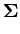 |
|
 |
(3.11) |
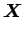 |
|
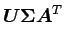 |
(3.12) |
なお、ここでの各記号の意味は3.1 項と同じであり、先に述べたように結合係数(固有ベクトル)が右特異ベクトルで与えられていることが分かる。データ行列はこのように表せるので、式(3.12)の右辺の各行列から数行あるいは数列取り出すことで次元を圧縮することが出来る。その圧縮の方法としては、左特異ベクトルを用いて以下のように表せる。
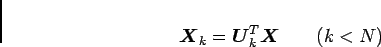 |
(3.13) |
の成分は式(3.9)のように添字の若いものほど大きく、ここから最初の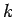 個を取り出して、との行列積により元のデータ行列を次元に縮約することが出来る。
個を取り出して、との行列積により元のデータ行列を次元に縮約することが出来る。
Deguchi Lab.
2011年3月4日