まずアスペクトモデルは、文書
![]() 中に存在する単語
中に存在する単語
![]() に伴う隠れ(非観測)変数
に伴う隠れ(非観測)変数
![]() に関する潜在変数モデルを指し、これを生成モデルを用いて表現すると、以下のように定義することが出来る。
に関する潜在変数モデルを指し、これを生成モデルを用いて表現すると、以下のように定義することが出来る。
この結果により観測データ![]() の組が得られ、その過程で
の組が得られ、その過程で![]() は破棄されることになる。これを結合確率モデルで表すと、次式のようになる。
は破棄されることになる。これを結合確率モデルで表すと、次式のようになる。
式(3.18)から分かるように、これはある観測データを引き起こした全ての隠れ変数を考慮しなければならない。また文書中の語句の分布![]() は
は![]() の凸結合から得られ、文書はクラスタに割り当てられずに、重み
の凸結合から得られ、文書はクラスタに割り当てられずに、重み![]() によって特徴づけられる。この重みは、クラスタモデルや教師無しの単純なベイズモデルによる事後確率とは大きく異なり、概念的でモデルとして優れているとHofmann氏は述べている。
によって特徴づけられる。この重みは、クラスタモデルや教師無しの単純なベイズモデルによる事後確率とは大きく異なり、概念的でモデルとして優れているとHofmann氏は述べている。
ここで![]() ,
, ![]() ,
, ![]() は尤度原理に従うことで、以下の対数尤度関数を最大化することよって決定される。
は尤度原理に従うことで、以下の対数尤度関数を最大化することよって決定される。
なお、この式において![]() は用語頻度、すなわち文書
は用語頻度、すなわち文書![]() 中に単語
中に単語![]() がいくつ存在するかを表す。ここで、ベイズの定理[11]を用いて条件付き確率
がいくつ存在するかを表す。ここで、ベイズの定理[11]を用いて条件付き確率![]() を反転させると、以下のようになる。
を反転させると、以下のようになる。
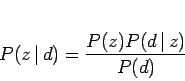 |
(3.20) |
これと式(3.17), 式(3.18)により以下の等価なモデルが得られ、実際の計算にはこの式を利用することになる。
より適切な計算結果を得る為には式(3.19)を最大化する必要があり、これを見積もる手続きとして、EM(Expectation Maximization)アルゴリズムが用いられる。このアルゴリズムの特徴としては、尤度が単調増加することが保証されており、初期段階の速度がニュートン法と同程度であることが知られている。その中身は2つのステップに分かれており、1つ目のEステップは![]() を始めとする現在のパラメータを見積もり、
を始めとする現在のパラメータを見積もり、![]() によって事後確率を計算する。2つ目のMステップはEステップによって計算された事後確率により、パラメータを更新する。ここで再びベイズの定理を用いてEステップを導くと、次に示す式が求まる。
によって事後確率を計算する。2つ目のMステップはEステップによって計算された事後確率により、パラメータを更新する。ここで再びベイズの定理を用いてEステップを導くと、次に示す式が求まる。
これは観測データの発生が隠れ変数によって説明されることを示しており、計算を進めることで以下のパラメータ更新に関するMステップの方程式が得られる。
この式(3.22) ![]() 式(3.25)までの収束手続きを繰り返すことで、式(3.19)に示す対数尤度関数の局所的最大値に近づくことが出来る。尤度を最大化することは語句の複雑さを減少させることと等価であり、これにより文書あるいは単語の繋がりを見つけやすくなる。この為、より尤度を高める為に、このEMアルゴリズムを改良した手法であるTEM(tempered EM)が提唱されている。これは決定論的焼きなまし法に非常に近く、エントロピー的な要素を取り入れたアルゴリズムである。具体的には式(3.22)に温度の逆数を表す
式(3.25)までの収束手続きを繰り返すことで、式(3.19)に示す対数尤度関数の局所的最大値に近づくことが出来る。尤度を最大化することは語句の複雑さを減少させることと等価であり、これにより文書あるいは単語の繋がりを見つけやすくなる。この為、より尤度を高める為に、このEMアルゴリズムを改良した手法であるTEM(tempered EM)が提唱されている。これは決定論的焼きなまし法に非常に近く、エントロピー的な要素を取り入れたアルゴリズムである。具体的には式(3.22)に温度の逆数を表す![]() を導入して修正を加えたものであり、これは以下の式で表される。
を導入して修正を加えたものであり、これは以下の式で表される。
ここで![]() の時は標準のEステップとなるが、
の時は標準のEステップとなるが、![]() の時はベイズの定理に関する部分だけが対数的に増加することになる。この
の時はベイズの定理に関する部分だけが対数的に増加することになる。この![]() は尤度の増加が見られなければ
は尤度の増加が見られなければ
![]() によって徐々に減少させ、これによってTEMは収束アルゴリズムを定義し、過剰適合を回避出来るという利点を持つことになる。このように焼きなまし法の主旨に多少反するが、温度の上昇によりデータを鍛える(temper)というのがこのTEMの特徴である。
によって徐々に減少させ、これによってTEMは収束アルゴリズムを定義し、過剰適合を回避出来るという利点を持つことになる。このように焼きなまし法の主旨に多少反するが、温度の上昇によりデータを鍛える(temper)というのがこのTEMの特徴である。
PLSAの問題点としては確率的な変数を用いる為に初期値依存性があることで、これによって大きく結果が変わることがある。また、隠れ変数の数や反復回数、![]() を減少させる時の係数である
を減少させる時の係数である![]() などのパラメータを上手く決定する必要があり、ここがLSAにはないデメリットとなっている。
などのパラメータを上手く決定する必要があり、ここがLSAにはないデメリットとなっている。
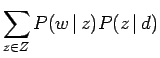
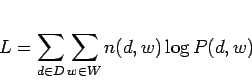
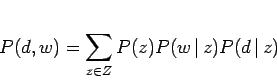
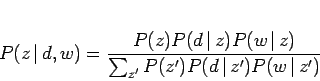
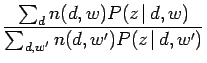
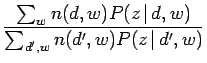
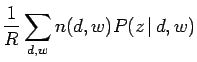
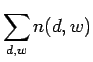
![\begin{displaymath}
P_{\beta} (z \, \vert \,d, w) = \frac
{P(z)[P(d \, \vert \...
...{\sum_{z'} P(z')[P(d \, \vert \,z')P(w \, \vert \,z')]^\beta}
\end{displaymath}](img127.png)