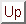


Next: LSAについて
Up: データ整理
Previous: データ整理
目次
シラバスと用語の行列生成
TermExtractを用いる際には複合語が生成されることになるが、これは果たして類似度を計算するのに有効と言えるのだろうか。例えば「リアクタンス二端子網」というような複合語があった時、これは「リアクタンス」にも「二端子網」にも一致しないことになる。このような専門的過ぎる語句は他の教科に存在せず、類似度の上昇に影響を与えないものになると考えられる。その一方で「変圧器」のように「変圧」と「器」を合成して一般的な語にするはたらきもある為、複合語を作るか作らないかは一長一短であると言える。そのどちらが良いかを調べる為にも、複合語を生成した場合としなかった場合の2つのデータを用意することにした。
LSAを実行する時には行を用語、列を文書とした表5.1のようなデータ行列が必要になるので、これを前節で述べた特別な用語を考慮して作成した。この用語群は各シラバスのもつ用語を全て集めたもので、重複するものは削除した。一方、文書群は各教科名に当たり、1E電気電子設計製図から5Eまで順に並べていった。
行列の要素は重要度を表すがほとんど0となり、疎行列であることが分かる。テキストデータの処理においてはこのような行列になることが多く、その性質を考慮して計算時間を短縮しようとするアルゴリズムが存在している。文書数は58個となった。
Deguchi Lab.
2012年3月9日