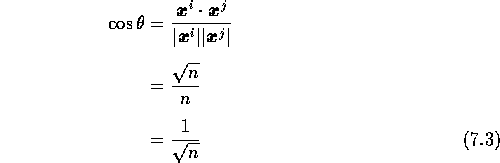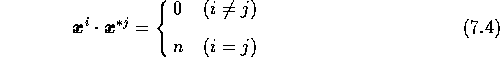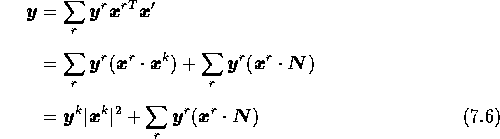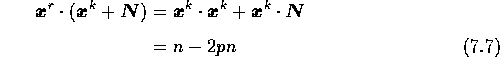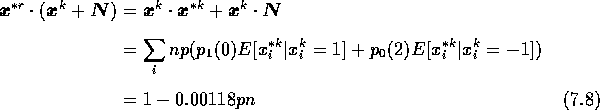第6章までに述べたことを確認するため、電子計算機上でランダム層モデルについて、実験を行なった。
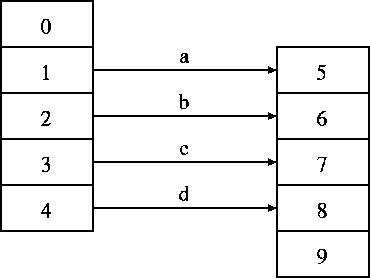
図 7.1 を参考にして次のような実験を行なった。(図 7.1 において、例えば 、a はパターンを学習させる際に 1 と 5 のパターンを同一パターンとすることを意味する。)
尚、実験は全て1層あたりのニューロン数173、学習パターン15、サイクル周期5、サイクル数3とした。 また、学習パターンは乱数を用いて作成したランダムパターンとし、 学習パターンに乱数によってノイズを加えたものを初期値とする。 ノイズを加える範囲は15%から50%まで1%刻みで増加させ、各値で100通りの初期値について測定を行なった。
ここで、パターンをランダムパターンとした理由を示す [1] 。
連想記憶モデルでは、第5章にて述べたようにパターンが互いに直交していることが大切である。
各成分が1か0かをほぼ等しい確率でとる場合、
パターンベクトル ![]() の大きさは、
ベクトルの成分の数を n とすれば、
の大きさは、
ベクトルの成分の数を n とすれば、
であり、他のベクトル ![]() との内積は
との内積は
となり、平均値が0、標準偏差が ![]() 程度にばらついている。
故に
程度にばらついている。
故に ![]() と
と ![]() の角度
の角度 ![]() は
は
程度で、 n が大きければ十分直交状態に近くなる。 このために実験ではランダムパターンを用いた。
数字やアルファベットなどの文字パターンはランダムパターンと違い、 成分の値が1をとる確率と0をとる確率が等しいとはいえず、直交状態とはいえない。 そのため、このような場合には直交学習を行なう [5] 。
直交学習とは、
となるベクトル ![]() を求めて、シナプス荷重を
を求めて、シナプス荷重を
とすることで、ランダムパターンによる直交化と同じ効果がでる。
上記の理論はデータに誤りのない場合のことで、ノイズが入った場合の誤り訂正能力について考えてみる。
学習パターンに確率 p でノイズが加わるとする。
パターン ![]() にノイズが加わったパターンを
にノイズが加わったパターンを
![]() とすれば、式(5.9)は
とすれば、式(5.9)は
となる。 N を加えることによって、確率 p で数値1が0に、 0が1に変わるため、 N は確率 p/2 で値2、 確率 p/2 で値0をとるベクトルである。 式(7.6)の右辺第2項が妨害項である。 r = k での妨害項は
であり、本来の値 n に対して -2pn/n = -2p の割合で影響が出る。
直交学習を行なった場合、 ![]() を理論的に求めるのは厄介であるため数値計算による結果のみを示す。
ランダムパターンと同様に r = k で
を理論的に求めるのは厄介であるため数値計算による結果のみを示す。
ランダムパターンと同様に r = k で
ここで E はそれぞれの ![]() の平均値、
の平均値、 ![]() は各要素が1をとる確率で本実験では0.264、
は各要素が1をとる確率で本実験では0.264、
![]() は0をとる確率で今回は0.736である。
本来の値1に対して -0.00118 p n の割合で影響が出る。
これに n = 173 を代入すれば直交学習の方が妨害項の割合が大きくなる。
また、
は0をとる確率で今回は0.736である。
本来の値1に対して -0.00118 p n の割合で影響が出る。
これに n = 173 を代入すれば直交学習の方が妨害項の割合が大きくなる。
また、 ![]() でランダムパターンでは妨害項の平均値が1であるのに対し、
文字パターンでは妨害項の平均は正の値を持っており、これも影響してくる。
この結果から、ある程度ニューロン数が大きくなり、更に1と0が出る確率に差が出てくると、直行学習の誤り訂正能力が悪くなることが確認された。
でランダムパターンでは妨害項の平均値が1であるのに対し、
文字パターンでは妨害項の平均は正の値を持っており、これも影響してくる。
この結果から、ある程度ニューロン数が大きくなり、更に1と0が出る確率に差が出てくると、直行学習の誤り訂正能力が悪くなることが確認された。
すなわち、記憶能力を最大限に引き出そうとするならば、1と0の出る確率がほぼ等しく、ランダムに近い現れ方をするような符合化をするしかないといえる。 本論文ではニューラルネットワークの特性の限界を調べるため、ランダムパターンを用いた。