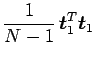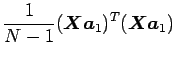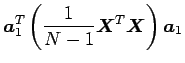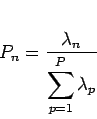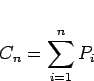まず![]() 個のデータ
個のデータ
![]() があった時、
があった時、![]() 個の主成分
個の主成分
![]() とこれらの関係は、次式のような互いに独立な線形結合として表される。
とこれらの関係は、次式のような互いに独立な線形結合として表される。
ここで![]() は第
は第![]() 主成分と呼ばれ、その結合係数
主成分と呼ばれ、その結合係数![]() は以下の式を満たす必要がある。
は以下の式を満たす必要がある。
主成分が多くの情報をもつようにする為には、この結合係数を上手く決めてやる必要があり、それにはデータの分散に着目する。この例を示す為に図 3.1のような2次元のデータを考える。この図において、データのばらつきが最も大きくなる方向に着目すると、![]() という軸が出来ることが分かる。これが第1主成分となり、このような軸が出来るように式(3.1)の結合係数を決定するのである。しかし、これだけではデータの持つ情報を大まかに表したとは言えない。そこで次にデータのばらつきが大きい軸、すなわち第2主成分
という軸が出来ることが分かる。これが第1主成分となり、このような軸が出来るように式(3.1)の結合係数を決定するのである。しかし、これだけではデータの持つ情報を大まかに表したとは言えない。そこで次にデータのばらつきが大きい軸、すなわち第2主成分![]() をとり、これによって情報量の損失を最小にしながら、
をとり、これによって情報量の損失を最小にしながら、![]() から得られる特性を上手く把握することが出来る。
から得られる特性を上手く把握することが出来る。
ここで、もし全てのデータが一直線上に並んだならば第2主成分は0となり、![]() はデータの分析に全く役に立たないことになる。よって、データのばらつきである分散が大きいほど、情報を多く含んでいると言えるのである。以上の例は2次元という簡単な例であった為に、主成分分析はあまり役に立たないが、高次元であるとその効果は顕著に現れる。
はデータの分析に全く役に立たないことになる。よって、データのばらつきである分散が大きいほど、情報を多く含んでいると言えるのである。以上の例は2次元という簡単な例であった為に、主成分分析はあまり役に立たないが、高次元であるとその効果は顕著に現れる。
結合係数の決定の仕方としては、特異値分解に基づくものとスペクトル分解に基づくものがある。第![]() 主成分の結合係数
主成分の結合係数
![]() は、前者においてはデータ行列
は、前者においてはデータ行列
![]() の
の![]() 番目に大きな特異値
番目に大きな特異値![]() に対応する右特異ベクトルとして与えられ、後者においては行列
に対応する右特異ベクトルとして与えられ、後者においては行列
![]() の
の![]() 番目に大きな固有値
番目に大きな固有値![]() に対応する固有ベクトルとして与えられる。前者については3.2 項でもう少し詳しく説明することにして、ここでは後者について取り扱う。
に対応する固有ベクトルとして与えられる。前者については3.2 項でもう少し詳しく説明することにして、ここでは後者について取り扱う。
ここでは分かりやすく第1主成分を取り上げて、結合係数が固有ベクトルで表されることを示す。まず、第1主成分の分散![]() は式(3.3)のように与えられ、ここで
は式(3.3)のように与えられ、ここで
![]() は第1主成分得点と言い、これは
は第1主成分得点と言い、これは![]() 番目のデータに対応する第1主成分の値をベクトルにまとめたものである。また
番目のデータに対応する第1主成分の値をベクトルにまとめたものである。また
![]() は分散共分散行列を表す。ここで、
は分散共分散行列を表す。ここで、![]() で割っていることから標準分散ではなく不偏分散を用いていることが分かり、後述するRの関数もこちらを採っているようである。不偏分散は、母集団が大きく標本が少ない時に向く。
で割っていることから標準分散ではなく不偏分散を用いていることが分かり、後述するRの関数もこちらを採っているようである。不偏分散は、母集団が大きく標本が少ない時に向く。
第1主成分を最大にするには、この式(3.3) : ![]() を式(3.2) :
を式(3.2) : ![]() の下で最大となるようにすれば良く、それにはラグランジュの乗数法から式を導き、それを結合係数
の下で最大となるようにすれば良く、それにはラグランジュの乗数法から式を導き、それを結合係数
![]() で偏微分して
で偏微分して![]() とおけば良い。
とおけば良い。
ここで![]() は単位行列を示し、式(3.5)のように固有方程式が得られた。このことより、結合係数
は単位行列を示し、式(3.5)のように固有方程式が得られた。このことより、結合係数
![]() は分散共分散行列
は分散共分散行列
![]() の固有値
の固有値![]() および固有ベクトルとして与えられることが分かる。この固有値が大きい主成分ほど情報を多くもっていることになり、大きい固有値から順に、その対応する主成分が第1主成分, 第2主成分,
および固有ベクトルとして与えられることが分かる。この固有値が大きい主成分ほど情報を多くもっていることになり、大きい固有値から順に、その対応する主成分が第1主成分, 第2主成分, ![]() , 第
, 第![]() 主成分に当たる。また式(3.3)に式(3.4), 式(3.2)を代入することにより、以下の式が導かれる。
主成分に当たる。また式(3.3)に式(3.4), 式(3.2)を代入することにより、以下の式が導かれる。
これは先程述べたように分散が情報の大きさを決定していることを示しており、最大値をとるべき![]() は最大固有値に等しい必要がある。これまでのことを以下第
は最大固有値に等しい必要がある。これまでのことを以下第![]() 主成分まで同様に導くことが出来る。以上のことより、結合係数
主成分まで同様に導くことが出来る。以上のことより、結合係数
![]() は最大固有値に対する固有ベクトルとして求められ、これがスペクトル分解に基づく結合係数の決め方になる。なお、ここまで分散共分散行列を使って主成分分析を行う方法を記したが、相関係数行列を使って行う方法もある。どちらも一長一短であり、どちらが良いとは一概には言えない。
は最大固有値に対する固有ベクトルとして求められ、これがスペクトル分解に基づく結合係数の決め方になる。なお、ここまで分散共分散行列を使って主成分分析を行う方法を記したが、相関係数行列を使って行う方法もある。どちらも一長一短であり、どちらが良いとは一概には言えない。
ここまで単に式を追ってきただけであったが、実際に測定や調査を行う時には、各項目は異なる単位系となることが多い。よって、単位の取り方により異なる主成分が得られることになり、同じ単位系であっても分散が大きく異なる項目に対して主成分分析を行えば、大きい方の影響を強く受けることになり、正しい結果が得られなくなる。そこで全ての項目を何らかの手法を用いて標準化する必要が出てくるが、広く利用されている方法として、各項目において平均1・分散1となるように正規化するものがある。このような処置を施すことで、得られる結果の信頼性を高めることが出来る。
さて、主成分分析によりデータを総合的な指標である主成分として表せることを述べてきたが、その主成分はいくつほど採用してデータを圧縮すれば良いのだろうか。その選択の方法としては、以下に示すようなものがある。
これらをもう少し詳しく説明すると、1は先述したように平均1・分散1としたことで、分散(固有値)がこの標準化された値である1よりも大きければ、説明力のある主成分として用い得るという考えに基づいている。2はある固有値とその次の固有値の差が小さければ、主成分の採用・非採用の区別にあまり意味はないという考えに基づいている。3はデータから得られる全情報の何割かを含んでいれば良いという考えに基づくもので、普通60%〜80%に達するまでの主成分数を採用する[7]。累積寄与率(cumulative propotion)は寄与率(proportion)に関係するものであり、寄与率は次式で表される。
このように、ある主成分の固有値が表す情報が、全ての情報の中でどの程度の割合を占めているかを表すのが寄与率である。一方、累積寄与率は次に示すように第![]() 成分までの寄与率の総和で表される。
成分までの寄与率の総和で表される。


![\includegraphics[scale = 0.9]{fig01.eps}](img24.png)