Next:
R言語
Up:
実験に使用した技術
Previous:
潜在的意味インデキシング
目次
クラスター分析
クラスター分析とは、与えられたデータをいくつかの集合に分類するデータ解析手法のことである。分類された後の集合をクラスターと呼ぶ。クラスター分析には、分類が階層的になる階層的クラスター分析とクラスター数を指定して分類する非階層的クラスター分析がある。この研究では階層的手法を使用するので階層的クラスター分析について説明する。階層的クラスター分析とは、データ間の類似度または非類似度に基づいて、最も似ているデータから順次集めてクラスターを形成していく。R言語ではクラスターを形成していく様子を樹形図で示すことができる。階層的クラスター分析はクラスター間の距離を決める方法にいくつかの種類があるが、その中から最近隣法、最遠隣法、群平均法、ウォード法について説明する。
最近隣法
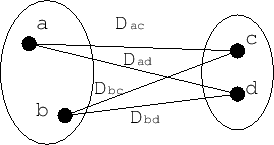
2つのクラスターの中から、最も近いデータ間の距離を2つのクラスターの距離とする方法。Figure
3.2
(a)では、クラスターabとクラスターbcの距離として距離
を選択し、Figure
3.2
(b)のクラスターができる。
最遠隣法
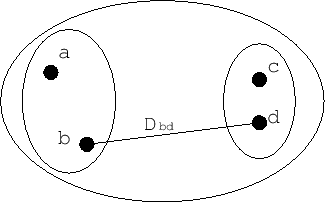
2つのクラスターの中から、最も遠いデータ間の距離を2つのクラスターの距離とする方法。Figure
3.2
では、クラスターabとクラスターbcの距離として距離
を選択し、Figure
3.2
のクラスターができる。
群平均法
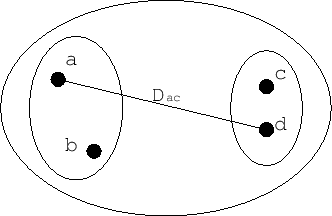
2つのクラスターの中から、それぞれデータを一つずつ選び距離を求め、それらの距離の平均値を2つのクラスターの距離とする方法。Figure
3.2
(a)では、クラスターabとクラスターbcの距離として、距離
の平均を計算し、新しいクラスターを形成する。
ウォード法
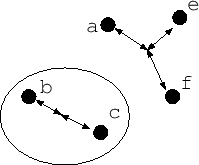
2つのクラスターを融合した際に、群内の分散と群間の分散の比を最大化する基準でクラスターを形成していく方法。Figure
3.2
(d)の場合、データb、cからなるクラスターが形成される。
最近隣法と最遠隣法にはそれぞれチェーンと拡散現象という性質があるので、次にその説明を示す。
チェーン
クラスターが大きくなるにつれ、他のデータと最短距離を多く持つようになり、次のクラスターの形成の候補に選ばれやすくなる現象。
拡散現象
クラスターが大きくなるにつれ、他のデータと最長距離を多く持つようになり、次のクラスターの形成の候補に選ばれにくくなる現象。
図 3.2:
cluster
(a) sample
(b) single
*[10mm]
(c) complete
(d) Ward
Deguchi Lab.
2017年3月6日