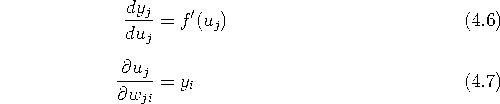この章ではニューラルネットワークに学習をさせるための学習則の説明をする。
本研究での学習には、
バックプロパゲーション法(back-propagation, 誤差逆伝搬法)という学習則を用いるが、
この節ではまず、
第二章で説明したニューロンの特性を一般化する。
ある素子 j は、
他の素子 i の出力 ![]() を入力として受け、
重み
を入力として受け、
重み ![]() をかけて加えたものを入力の総和
をかけて加えたものを入力の総和 ![]() とする。
とする。
そして、
出力 ![]() は入力の総和に単調増加関数 f を施したもので表されることにする。
は入力の総和に単調増加関数 f を施したもので表されることにする。
ただし、 しきい値は重みの一つとして含まれていると考える。 ここで、 出力関数 f が階段関数であれば、 素子は第2章で説明したものと同じになる。 ここでは、 出力関数 f としてシグモイド関数を用いることにする。 シグモイド関数は、 0から1までの連続した値をとる関数なので微分可能であり、 後に解析的に問題を解くことが可能になる。
次に、
神経回路における学習を一般化して考える。
![]() をある入力ベクトル c に対して出力素子 j が出すべき望ましい出力、
をある入力ベクトル c に対して出力素子 j が出すべき望ましい出力、
![]() をその時の出力素子 j の実際の出力とした時、
学習の評価として、
次のような``誤差関数 E '' を考える。
をその時の出力素子 j の実際の出力とした時、
学習の評価として、
次のような``誤差関数 E '' を考える。
このような形の誤差関数を最小にする手続きを一般に``最小2乗誤差``(least mean square,LMS)法という。
![]() はその時の素子間の結合の強さ、
すなわち重み
はその時の素子間の結合の強さ、
すなわち重み ![]() で決まるため、
誤差関数も重みに関して陰に定義された関数となる。
したがって、
各重みの値を軸としてできる空間を考え、
さらにこの誤差関数 E によって定義される値を高さと考えれば、
E は重み空間上の超曲面として``誤差曲面''を与えることになる。
任意の重み状態から、
この誤差曲面の極小値に達するには、
例えば各重みを、
で決まるため、
誤差関数も重みに関して陰に定義された関数となる。
したがって、
各重みの値を軸としてできる空間を考え、
さらにこの誤差関数 E によって定義される値を高さと考えれば、
E は重み空間上の超曲面として``誤差曲面''を与えることになる。
任意の重み状態から、
この誤差曲面の極小値に達するには、
例えば各重みを、
![]() に比例した量
に比例した量
ずつ変化させていけばよいことになる。 これは、 誤差曲面上を最も急な傾斜方向に進んでいくことに相当し、 このような学習則を一般に 最急降下法(gradient decent method)という。
さて、 式(4.1)、 式(4.2)のように素子の性質が定義されていれば、 式(4.4)は合成関数の微分公式により、
![]()
と展開できる(添字 c は省略した)。 式(4.1)(4.2)を微分して代入すれば、
であるので、 結局式(4.4)は、
となる。
中間層が学習しない場合、
![]() の項は
式(4.3)を微分することにより簡単に
の項は
式(4.3)を微分することにより簡単に
![]()
と求めることができるので、式(4.8)より、
![]()
という学習則が得られる。 これを一般化デルタルールと呼ぶ。 例えば f がシグモイド関数で与えられる場合
より
![]()
という形になる。
式(4.11)の方法では、
すべての入出力パターンが与えられた後に
はじめて重みを変化させることになるが、
![]() が十分に小さければ、
パーセプトロンのように各入出力が与えられるごとに重みを反復的に変化させる。
すなわち
が十分に小さければ、
パーセプトロンのように各入出力が与えられるごとに重みを反復的に変化させる。
すなわち
![]()
としても、 全体の変化量は最急降下法とほぼ等しくなる。