| 地点 | 降水の有無の
適中率[%] |
最高気温の
予測誤差(RMS)[ |
最低気温の
予測誤差(RMS)[ |
| 東京都 東京 | 62.85 | 2.90 | 1.99 |
| 北海道 稚内 | 62.60 | 2.68 | 2.39 |
| 秋田県 秋田 | 60.60 | 2.81 | 1.99 |
| 新潟県 新潟 | 59.75 | 2.93 | 1.91 |
| 長野県 軽井沢 | 62.55 | 3.58 | 2.25 |
| 滋賀県 彦根 | 62.30 | 2.56 | 1.83 |
| 和歌山県 潮岬 | 65.50 | 2.17 | 1.96 |
| 香川県 高松 | 64.85 | 2.59 | 1.87 |
| 島根県 松江 | 59.00 | 2.80 | 1.99 |
| 沖縄県 那覇 | 65.35 | 1.80 | 1.59 |
| 降水の有無の適中率 | 気温の予測誤差 | ||||
| 地点 | 良い月 | 悪い月 | 良い月 | 悪い月 | |
| 予測が | 東京都 東京 | 1月、2月 | 9月、11月 | 8月 | 4月 |
| 良い地点 | 香川県 高松 | 1月、2月 | 6月、7月、9月 | 8月 | 3月、4月 |
| 予想が | 島根県 松江 | 8月 | 2月、3月 | 7月、10月 | 3月、4月 |
| 悪い地点 | 新潟県 新潟 | 8月、12月 | 3月、4月 | 1月、6月、12月 | 3月、4月 |
| 地点 | 予測雨、実際晴れの確率 [% ] | 予測晴れ、実際雨の確率[% ] | |
| 予測が | 東京都 東京 | 46.7 | 4.75 |
| 良い地点 | 香川県 高松 | 26.5 | 8.65 |
| 予測が | 島根県 松江 | 24.8 | 15.4 |
| 悪い地点 | 新潟県 新潟 | 26.65 | 13.6 |
降水量の入力データをを段階化して自己組織化マップに学習を行い、 気象予測を行ったときの予測精度を表5.9に示す。
表5.9を見ると、実験1のとき予測精度が低かった新潟、秋田など降水量の多い地点の
降水の有無の適中率が60%程度と10%程、予測精度が上がっていることがわかる。
しかし、降水の有無の適中率の予測精度の高かった高松や東京などでは、
予測精度が62%程度と4%程、予測精度が下がってしまった。
気温の予測誤差では、殆どの地点において
最高気温、最低気温の予測誤差がともに0.5![]() Cほど小さくなっていることがわかる。
これは、降水量を段階化することで、入力データが単純になり、
気象のパターン分類が単純になったためと考えられる。
そのため、パターン分類がうまく行われ、気温の予測誤差が小さくなったと考えられる。
また実験1と同様に、降水の有無の適中率が高くても、気温の予測誤差が大きかったり、その反対の場所もあり、
降水の有無の適中率は気温の予測誤差には関係がないことがわかる。
Cほど小さくなっていることがわかる。
これは、降水量を段階化することで、入力データが単純になり、
気象のパターン分類が単純になったためと考えられる。
そのため、パターン分類がうまく行われ、気温の予測誤差が小さくなったと考えられる。
また実験1と同様に、降水の有無の適中率が高くても、気温の予測誤差が大きかったり、その反対の場所もあり、
降水の有無の適中率は気温の予測誤差には関係がないことがわかる。
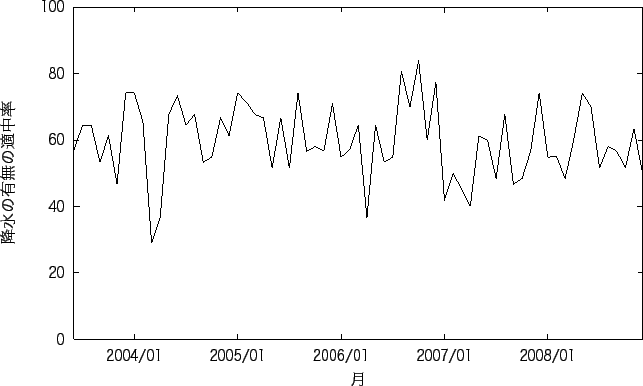
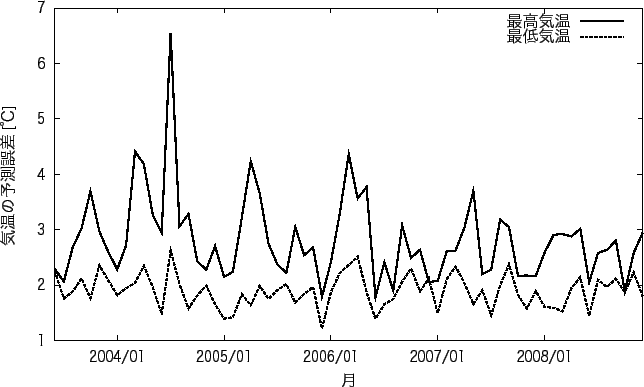
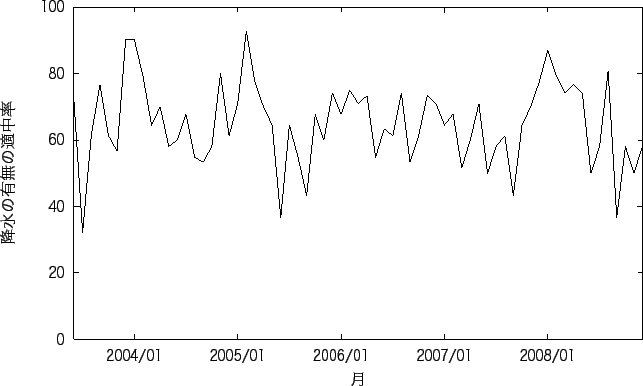
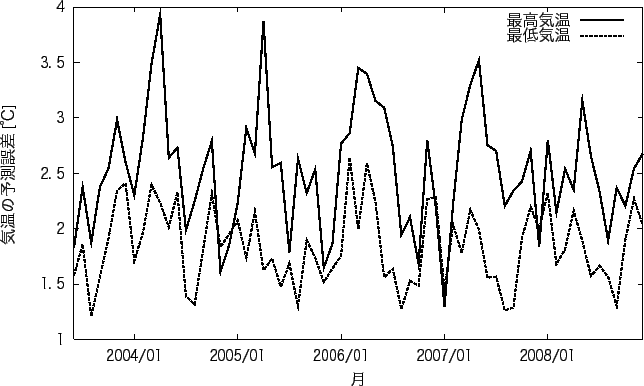
降水の予測の良い地点と悪い地点の 1ヶ月ごとの降水の有無の平均適中率を図5.5、図 5.7に、 1ヶ月間ごとの気温の平均予測誤差を図5.6、図5.8に示す。 また、降水の有無の適中率が良い地点と悪い地点における予測精度が良い月と悪い月を表5.10に、 予測の失敗の確率を表5.11に示す。
図5.5、図5.8は実験1の結果に比べ 形は似ているが全体的に誤差が小さくなっていることがわかる。 また、実験1では予測が悪くなった2008年も例年と同様程度の誤差になっていることがわかる。 図5.5では、実験1の時に予測が悪かった6月の予測が良くなり、40%以下の適中率が 殆どなくなっていることがわかる。 図5.8では実験1とグラフの形は似ているが全体的に予測精度が下がっていることがわかる。
表5.10をみると、 予測が良い地点の降水の有無の適中率の良い月は、1、2月と冬であり、 適中率の悪い月は、9月と秋であることがわかる。 予測の悪い地点の適中率の良い月は8月と12月と夏と冬であり、 悪い月は3月と春であることがわかる。 気温の予測誤差では、予測の良い地点の誤差の少ない月では、8月となり、誤差の多い月は4月となった。 予測の悪い地点の誤差の少ない月は、1、6、7、10、12月と決まっていない。 それに対して、誤差の多い月は、3、4月と春である。 気温の誤差では、予測が良い地点、悪い地点に関わらず春に精度が悪くなることがわかる。 また予測が悪い地点では、特に良い月はなく、春以外であれば どの月でも同じ程度の予測精度であるといえる。
表5.11をみると 実験1と同様に予測の失敗では、予測が晴れ、実際が雨の確率に比べて 予測が雨、実際が晴れの確率の方が多くなっている。 しかし実験1の結果と比べて予測精度の上がった新潟や松江では、 多少予測が晴れ、実際が雨の確率が上がったが、 それ以上に予測が雨、実際が晴れの確率が下がっており、 二つの失敗の確率の差が小さくなっている。 それに対して、実験1の結果と比べて予測精度の下がった 東京や高松では、予測が雨、実際が晴れの確率が上がり、 予測が晴れ、実際が雨の確率が下がっていることがわかる。 これは実験1の予測が悪かった地点の結果に似ているといえる。
予測が悪くなった原因として降水の有無をわける閾値が問題であると考えられる。 今回の方法では、降水量を出すことが困難であるため、降水の入力データ全体から平均値を求め、 それを閾値として使うことで降水の有無の予測を行った。 この閾値が、松江や新潟など予測精度の良くなった地点では0.49、0.56であった。 それに対し、東京や高松など予測精度の悪くなった地点では、0.27、0.32と小さな値であった。 そのため、降水量の多い松江や新潟であれば、閾値がある程度の大きさを持つため、降水の有無の予測が 行いやすく予測精度が良くなるが、 降水量の少ない東京や高松では、閾値が小さく、予測を行うと雨になる確率が高くなってしまう。 そのため、降水の有無の予測精度が下がってしまうと考えられる。
これらの結果から、降水量を段階化することにより降水量の多い地点であれば 予測精度が高くなることがわかった。 また、降水量を段階化することで、 気温の予測誤差をあげることができた。 これらより、入力データに工夫を加えることで、降水の有無の適中率、気温の予測誤差ともに 予測精度をあげることが可能であるといえる。 その反面、降水量の少ないところでは、降水の有無の適中率が下がってしまった。 これに対しては、学習結果の降水データから閾値を求める、 降水量に応じて降水のデータの変更方法を変える などの工夫を必要であると考えられる。 そのため、入力データを工夫することにより、予測方法が今回の方法に比べて複雑になる可能性がある。