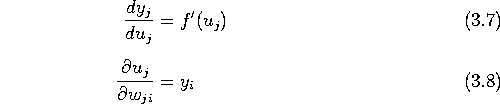バックプロパゲーションについて説明する前に、その考えの基となる一般化デルタルールについて説明する。
まず、ニューラルネットワークを学習させることを考える。 ある入力パターンを与えた時、そのネットの出力とそのネットが出力すべき望ましい出力とを用いて学習の評価となる次のような誤差関数 E を考えると
![]() :ある入力パターン c に対する出力素子 j の出力。
:ある入力パターン c に対する出力素子 j の出力。
![]() :出力素子 j が出力すべき望ましい出力。
:出力素子 j が出力すべき望ましい出力。
となる。
このような形の誤差関数を最小にする手続きを一般に最小自乗平均誤差法という。
![]() はその時の素子間の結合荷重
はその時の素子間の結合荷重 ![]() で決まるため誤差関数も重みに対して陰に定義された関数となる。
従って、それぞれの重みと E によって定義される値を軸とした重み空間上の超曲面としての誤差曲面を E は与えることになる。
任意の重みの状態から、この誤差曲面の極小値に達するには、例えば各重みを
で決まるため誤差関数も重みに対して陰に定義された関数となる。
従って、それぞれの重みと E によって定義される値を軸とした重み空間上の超曲面としての誤差曲面を E は与えることになる。
任意の重みの状態から、この誤差曲面の極小値に達するには、例えば各重みを ![]() に比例した量
に比例した量
ずつ変化させていけば良いことになる。 これは、誤差曲面上をもっとも急な傾斜方向に進んでいくことに相当し、このような学習則を一般に最急降下法という。
さて、ある素子(ニューロン) j は他の素子 i の出力 ![]() を入力として受け、結合荷重
を入力として受け、結合荷重 ![]() をかけたものの総和を
をかけたものの総和を ![]() とする。
とする。
そして、出力 ![]() は入力の総和にシグモイド関数 f を施したもので表されることにする(但し閾値も一つの重みとして含まれると考える)。
は入力の総和にシグモイド関数 f を施したもので表されることにする(但し閾値も一つの重みとして含まれると考える)。
このように素子の性質が定義されていれば、式(3.2)は合成関数の微分公式より
と展開できる(添字 c は省略した)。 式(3.3),(3.4)を微分して代入すれば
であるので、結局式(3.2)は
となる。
パーセプトロンのように中間層が学習しない場合、 ![]() の項は 式(3.1) を微分することより簡単になり
の項は 式(3.1) を微分することより簡単になり
と求めることができるので式(3.9)より
という学習則が得られる。 これを一般化デルタルールと呼ぶ。 ここでシグモイド関数(式(3.5))を微分し
これを式(3.11)に代入すると
という形になる。
式(3.13)の方法では、全ての入出力パターンが与えられた後にはじめて結合荷重を変化させることになるが、 ![]() が十分に小さければパーセプトロンのように各入出力が与えられるごとに結合荷重を変化させる。
すなわち
が十分に小さければパーセプトロンのように各入出力が与えられるごとに結合荷重を変化させる。
すなわち
としても全体の変化量は最急降下法とほぼ等しくなる。