上記の得点![]() は以下の式によって計算される。
は以下の式によって計算される。
ここで![]() は目標距離であり、
は目標距離であり、![]() と
と![]() がどれだけ離れていれば望ましいかを表す。実験ではこの値を2としたので、
がどれだけ離れていれば望ましいかを表す。実験ではこの値を2としたので、![]() が1で
が1で![]() が100に近ければ、多くの教科が一番似ているとされる教科と科目構成図において2つほどしか離れておらず、適切な類似度が求められていることが分かる。
が100に近ければ、多くの教科が一番似ているとされる教科と科目構成図において2つほどしか離れておらず、適切な類似度が求められていることが分かる。
この![]() を用いて4つのデータを比較した結果を表 4.4に示し、そのグラフを図 4.1に示す。この図を見ると、まず除去語は有った方が無い方よりも得点が高いことが分かる。これは前研究と一致する結果であり、用語一致によって類似度を計算する際には必要な処理であることがうかがえる。次に重要度に着目すると、重要度を考慮しなかった時より、考慮した時の方が若干得点が高いことが分かる。これは抽出教科数が1の時だけ例外となっているが、その他のデータでは得点は全て上回っている。しかしその差の大きさを見ると、重要度を考慮してもしなくてもさほど大きな違いはなく、出来れば考慮した方がよいという程度であると考えられる。
を用いて4つのデータを比較した結果を表 4.4に示し、そのグラフを図 4.1に示す。この図を見ると、まず除去語は有った方が無い方よりも得点が高いことが分かる。これは前研究と一致する結果であり、用語一致によって類似度を計算する際には必要な処理であることがうかがえる。次に重要度に着目すると、重要度を考慮しなかった時より、考慮した時の方が若干得点が高いことが分かる。これは抽出教科数が1の時だけ例外となっているが、その他のデータでは得点は全て上回っている。しかしその差の大きさを見ると、重要度を考慮してもしなくてもさほど大きな違いはなく、出来れば考慮した方がよいという程度であると考えられる。
| 除去語無 | 除去語有 | |||
| 重要度無 | 重要度有 | 重要度無 | ||
| 1 | 69.66 | 70.45 | 89.21 | |
| 2 | 62.14 | 64.74 | 71.08 | 74.13 |
| 3 | 56.20 | 60.77 | 64.97 | 67.76 |
| 4 | 52.74 | 54.61 | 61.76 | 63.45 |
| 5 | 48.27 | 51.56 | 58.03 | 57.79 |
除去語有の時にはそれなりに教科の繋がりを見つけられており、用語一致による簡易な計算方法でもあまり問題が無いように見受けられる。一方で、5Eオペレーティングシステムに一番近いのが3E電気機器であるといったような不審な点もあり、まだ得点を向上させる余地があると考えられる。このことから新しい手法を取り入れて、よりふさわしい繋がりを発見しようと試みた結果を第 5 章で後述する。
テキストマイニングは第 2 章でも述べたように新たな情報を発見することが望まれるが、ここでは教育課程表や科目構成図に記述されておらず、かつ正しいと言える教科の繋がりを発見することに当たると考えられる。この実験1でそれに当たるものは、4EJ情報理論と4E通信工学であった。通信工学においてはディジタル値を用いた通信方法や符号化があり、情報理論でも伝送路や符号化の仕組みを学習するので、両者は繋がりがある教科同士だと考えられる。また、どちらもC. E. Shannon氏に関係が深い学問である点もその要因と言える。
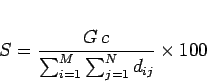
![\includegraphics[scale = 1.0]{fig03.eps}](img149.png)