| 地点 | 降水の有無の
適中率[%] |
最高気温の
予測誤差(RMS)[ |
最低気温の
予測誤差(RMS)[ |
| 東京都 東京 | 65.90 | 3.28 | 2.35 |
| 北海道 稚内 | 58.10 | 2.95 | 2.71 |
| 秋田県 秋田 | 51.30 | 3.12 | 2.31 |
| 新潟県 新潟 | 48.90 | 3.52 | 2.31 |
| 長野県 軽井沢 | 64.20 | 3.91 | 2.60 |
| 滋賀県 彦根 | 58.50 | 2.93 | 2.15 |
| 和歌山県 潮岬 | 60.50 | 3.13 | 2.92 |
| 香川県 高松 | 70.10 | 3.55 | 2.58 |
| 島根県 松江 | 51.30 | 3.34 | 2.48 |
| 沖縄県 那覇 | 63.25 | 3.12 | 2.41 |
| 地点 | 降水の有無の
適中率[%] |
最高気温の
予測誤差(RMS)[ |
最低気温の
予測誤差(RMS)[ |
| 東京都 東京 | 69.00 | 3.32 | 1.85 |
| 北海道 稚内 | 66.70 | 2.68 | 2.26 |
| 秋田県 秋田 | 60.45 | 3.72 | 2.30 |
| 新潟県 新潟 | 60.45 | 3.80 | 2.12 |
| 長野県 軽井沢 | 67.00 | 4.29 | 2.72 |
| 滋賀県 彦根 | 62.30 | 2.87 | 2.22 |
| 和歌山県 潮岬 | 65.80 | 3.19 | 2.38 |
| 香川県 高松 | 69.05 | 3.68 | 2.40 |
| 島根県 松江 | 64.00 | 3.22 | 2.39 |
| 沖縄県 那覇 | 64.80 | 3.55 | 2.37 |
| 降水の有無の適中率 | 気温の予測誤差 | ||||
| 地点 | 良い月 | 悪い月 | 良い月 | 悪い月 | |
| 予測が | 東京都 東京 | 1月 | 6月 | 8月、12月 | 4月、10月 |
| 良い地点 | 香川県 高松 | 1月、2月 | 6月、9月 | 8月 | 4月、5月 |
| 予想が | 島根県 松江 | 1月、2月 | 6月、9月 | 1月 | 9月 |
| 悪い地点 | 新潟県 新潟 | 12月 | 4月〜6月 | 6月、12月 | 4月、10月 |
| 地点 | 予測雨、実際晴れの確率 [% ] | 予測晴れ、実際雨の確率[% ] | |
| 予測が | 東京都 東京 | 23.5 | 10.85 |
| 良い地点 | 香川県 高松 | 16.8 | 13.1 |
| 予測が | 島根県 松江 | 41.7 | 7.0 |
| 悪い地点 | 新潟県 新潟 | 48.8 | 2.3 |
表5.1に示した各地点における実験結果を、表5.2に示す。 また、表5.3に前年の結果を示す[11]。
今回の結果を見ると降水の有無の適中率では、 高いところでは香川県高松の70.10%となり、 低いところでは新潟県新潟の48.90%となった。 また、全体的に50%前半と、60%前後に別れ、場所により適中の有無に大きな差が生まれたことがわかる。 この結果は前年のものに比べ全体的に5%ほど適中率が下がっていた。 しかし、降水の有無の適中率の最も高いところを比べると、 今回の方法では70.10%、前年の方法では69.05%と高くなっていることがわかる。 適中率の低いところをみると、新潟や島根など降水量の多い地点であることがわかる。 反対に、降水量の少ないところでは、適中率は高く、前年と比べても差がないことがわかる。
気温では、最高気温の予測誤差は約3![]() Cであり、最低気温の予測誤差は約2.5
Cであり、最低気温の予測誤差は約2.5![]() Cであることがわかる。
こちらは前年と比べても大きな差はなかった。
また、降水の有無の適中率が高くても、気温の予測誤差が大きかったり、その反対の場所もあり、
降水の有無の適中率は気温の予測誤差には関係がないことがわかる。
Cであることがわかる。
こちらは前年と比べても大きな差はなかった。
また、降水の有無の適中率が高くても、気温の予測誤差が大きかったり、その反対の場所もあり、
降水の有無の適中率は気温の予測誤差には関係がないことがわかる。
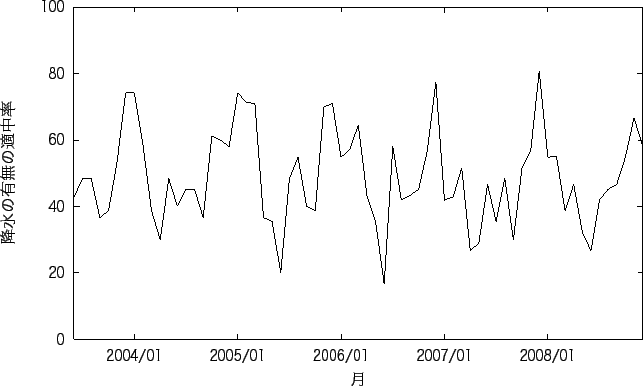
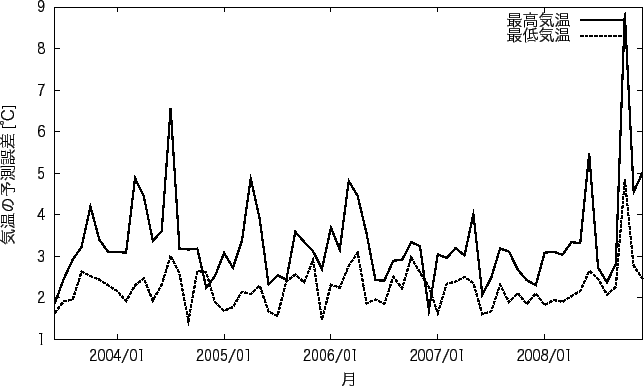
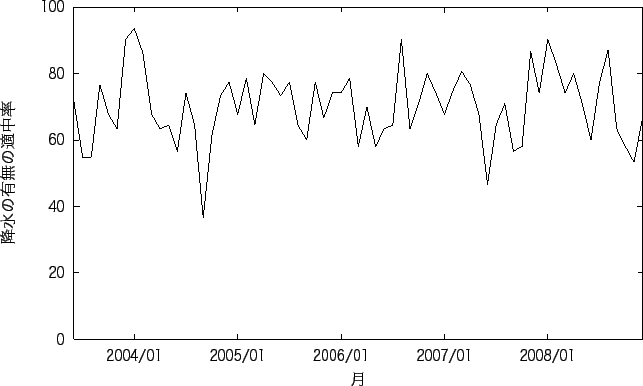
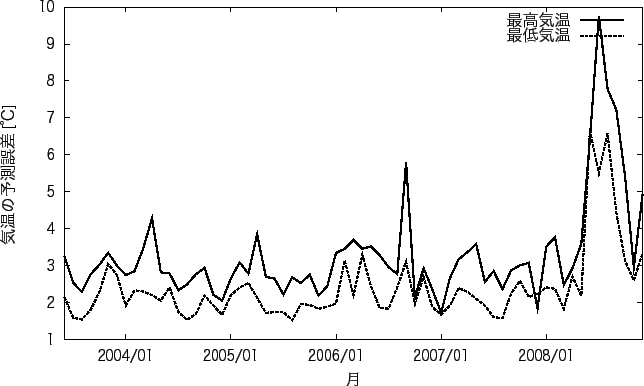
降水の予測の良い地点と悪い地点の 1ヶ月間ごとの降水の有無の平均適中率を図 5.1、図 5.3に、 1ヶ月間ごとの気温の平均予測誤差を図 5.2、図 5.4に示す。 また、実験1で予測の良い地点と悪い地点の予測精度が良い月と悪い月を表 5.4に、 予測の失敗の確率を表 5.5に示す。 図5.2、図5.4をみると2008年だけ異常に誤差が多くなっている。 新潟では、例年に比べ降水量が多く、また、その日とその翌日の気温の変化が大きいときが何度もある。 降水量が多いため、他の月と間違った予測をしたことが考えられ、また気温の変化も大きいため この月は他の月に比べ、大きな誤差が生じたといえる。 高松では、例年に比べ平均気温が高く、またそれが何日も続いた。 例年では気温が高い日の翌日は気温が下がることが多く、それを学習しているため、 この月の誤差は大きくなったと考えられる。 図5.1をみると、グラフの形が多少違いがあるが殆ど周期的に変化していることがわかる。 これは、毎年予測が行いやすい月、行いにくい月が決まっていることを示している。 図5.3では、どの月も同じような適中率であるが、稀に悪い月がある。 これは、気温と同じように、例年と違う気象であるために予測が下がっている。
表5.4をみると、降水の有無の適中率が良い月は 12月から2月であり、 悪い月では、6月と9月に多いことがわかる。 気温の予測が良い月では、8月と12月に多く、 悪い月では、4月と10月に多いことがわかる。 また、予測が良い地点と悪い地点どちらも予測が良い月、悪い月に差がないことがわかる。
表5.5をみると、予測の失敗では予測が良い地点、悪い地点ともに 予測が晴れ、実際が雨の結果に比べ、予測が雨、実際が晴れにより失敗するが多いことがわかる。 しかし、予測が悪い地点は、予測が良い地点に対してこの確率が40%以上と高く、 予測が晴れ、実際が雨と失敗する確率は7%以下と低いことわかる。
これらの結果より、降水の有無では、冬の精度が高く、春と秋の精度が低くなっている。 精度の低い春と秋では前年と同様、春と秋は似た気象であることが原因であるといえる。 今回の予測方法では、パターン分類を行った後、翌日の気象を学習させることで予測を行った。 そのため、春と秋は1日の気象のみでは、似た気象であるため パターン分類時に混ざってしまい、うまく分類できない。 そのため、翌日の気象は学習がうまく行えず予測精度が下がったと考えられる。 これに対して、夏と冬は気象データに特徴があり、パターン分類がうまく行える。 そのため、夏と冬は春と秋に比べ精度が高くなるといえる。 しかし今回の結果では、夏と冬ともに精度は高かったが、冬に比べ夏のほうが低くなってしまった。 この原因として、表5.5の結果より予測を雨とすることが多いことが考えられる。 夏と冬では、冬の方が夏に比べて降水は多い。 また、冬には降雪という独自のデータも持っている。 そのため、夏に比べ冬の方が精度が高くなったと考えられる。 また、気温の誤差が夏と冬に精度が高く、 春と冬に低くなる原因も同様の理由であるといえる。
上記の原因として示した予測を雨とすることが多い原因について考える。 今回の自己組織化マップによる翌日の学習では、平均的な降水量が多いとき、 また、台風などによる大雨により降水量が多いときがあると、 それらが広い範囲に影響を与えてしまう。 そのため、学習結果の降水量が全体的に増えてしまい、 予測を行うと殆どが雨という予測になってしまう。 それにより、予測が雨のときに外す確率が高くなり、 予測は晴れのときに外す確率が低くなったと考えられる。
以上の結果から、自己組織化マップによるパターンの分類及び翌日の気象の予測は、 降水量の少ない気象の地域であれば予測精度は高くなりやすく有用であり、 降水量が多くなるにつれ予測精度は下がるため有用ではないといえる。 また、夏と冬は予測精度が高いため、有用であるが、 春と秋は予測精度が低く信用性が低いといえる。 しかし、春と秋わけて学習、予測をすることで精度が高くなると考えられる。