ゲームでの評価をするにあたって、 出力誤差だけの評価だけでなく、他の視点での評価も求められる。 そこで実際にゲーム時の画面を見て、視覚的な評価および、 学習回数による比較を行なう。
ここでは内部記憶を用いたニューラルネットワークのうち、 100万回、1000万回、4000万回の学習時の結合荷重としきい値を用い、 同条件の下ゲームを開始し、視覚的評価を行なった。 ゲームの様子をそれぞれ学習回数ごとに分け、 100万回を図 6.6 に、 1000万回を図 6.7 に、 4000万回を図 6.8 に示す。
t=1ではそれぞれ視界にターゲットを捉え、 捕獲しようと前進する。
図 6.6 ではt=3でターゲットを視界で捉えた後、 そのターゲットへ近付くが、踏み込む移動距離が少ないことがわかる。
図 6.7 、図 6.8 から、t=2の時に 捉えたターゲットを、t=3でより正面に捉えているのは 4000万回学習した方ではなく、1000万回学習した方であることがわかる。 また、図 6.6 から、100万回学習時はほぼそのまま前進している。
しかし、t=3で捉えた2つのターゲットの近い方を的確に選び、 向きを修正したのは4000万回学習したほうである。 どちらも結果的には、そのターゲットを捕獲している。 多少の相違は見られるものの、 総合的な差は1000万回学習、4000万回学習ともにほとんどないと考えられる。
一方、100万回学習した方は、他と回転角度に大きな違いは見られないものの、 移動距離が目立って少なく、結果的にターゲットを捕獲できていない。 しかし、ゲームとしては全体的に成り立つような動きをしており、 100万回学習時と他の学習時との差は大きいものではないことがわかる。
次に、内部記憶を用いないニューラルネットワークのうち、 4000万回学習時のゲーム画面を図 6.9 に示す。
図 6.9 を見ると、ターゲットが視界に入ろうと 見向きもせずにただ回転を続けていることがわかる。 また、同時に移動も行なっているために、 ある程度の大きさの領域を作って回っていることもわかる。 これではターゲットが飛び込んでくるのを待つだけであり、 評価以前の問題といえる。 他の学習回数時でも全くと言っていいほど同様であり、 評価する必要がないと判断した。
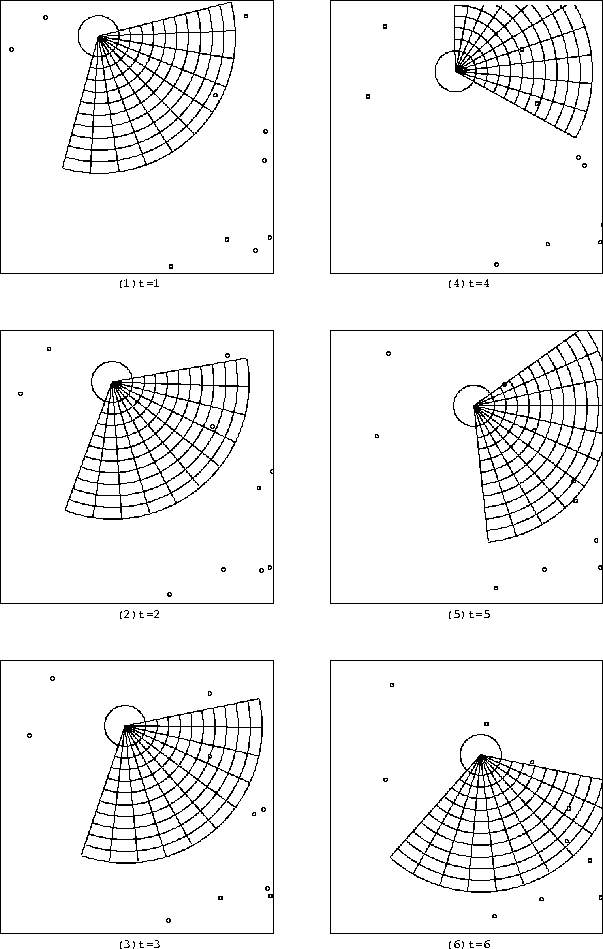
図 6.6: 内部記憶を用いたニューラルネットワークの100万回学習時のゲームの様子
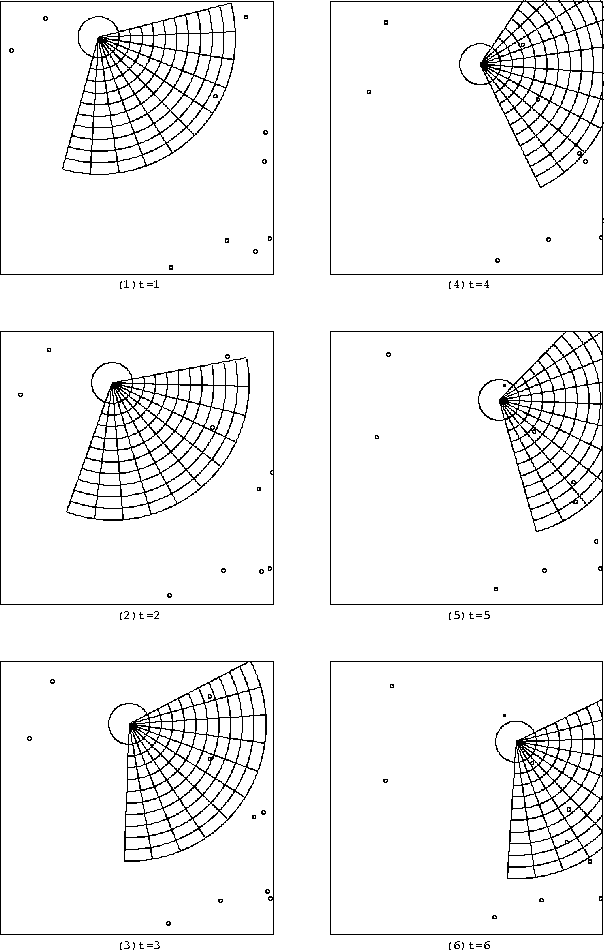
図 6.7: 内部記憶を用いたニューラルネットワークの1000万回学習時のゲームの様子
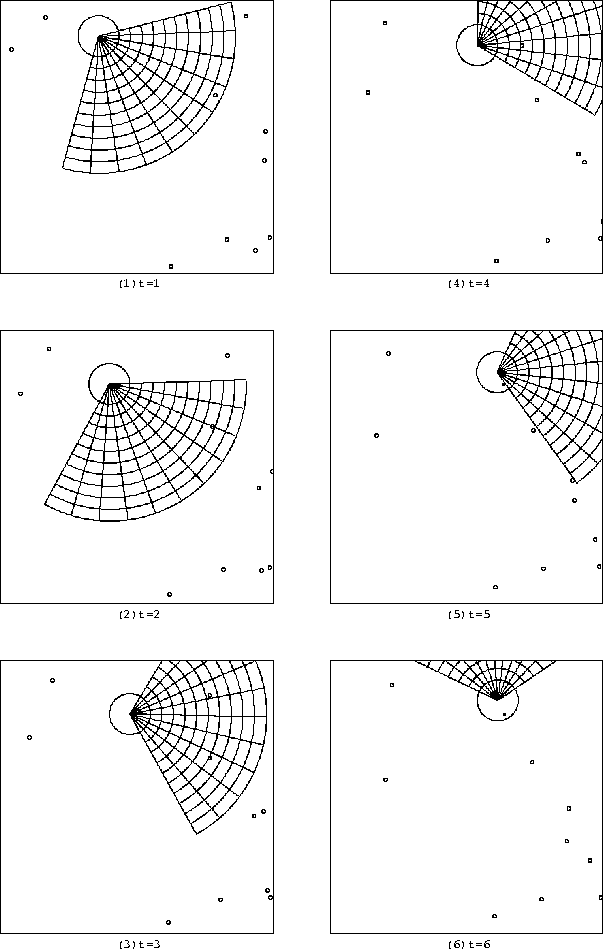
図 6.8: 内部記憶を用いたニューラルネットワークの4000万回学習時のゲームの様子
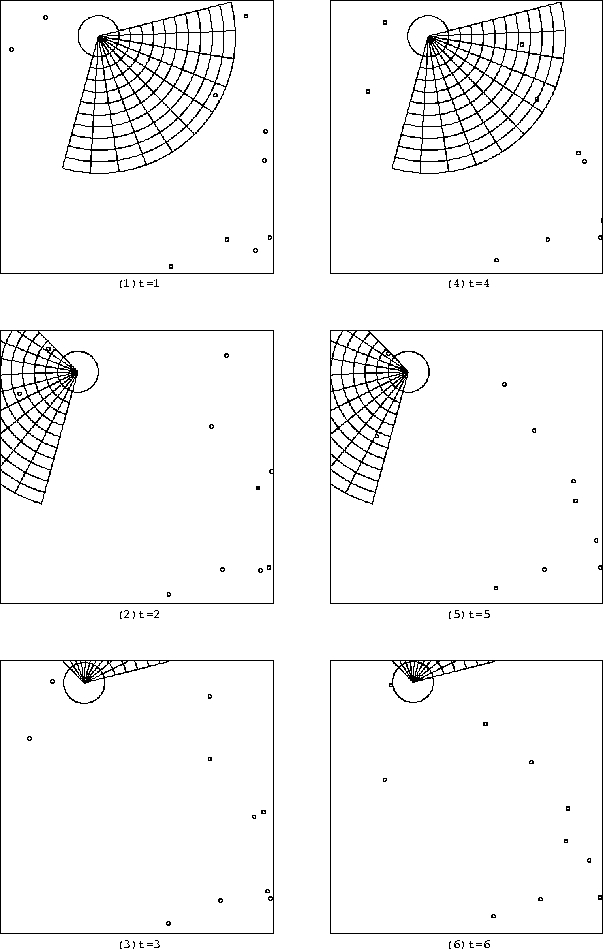
図 6.9: 内部記憶を用いないニューラルネットワークの4000万回学習時のゲームの様子