バイナリデータの解析、アーカイバ
1. 目的
計算機内で使われているファイルの種類について学ぶと共に、アーカイバの使い方とその特性について学ぶ。
2. 理論
2.1 バイナリファイルとテキストファイル
日常的に利用しているコンピュータのファイルは、全て0/1の列(bit列)で表されている。あらゆるデータは種類に応じて何らかの規約によってbit列を並べているが、そのデータの種類を示すのが拡張子である。代表的なものには、”.c”や”.docx”などがある。0/1の連続という点ではあらゆるファイルが2進のファイルであるが、歴史的経緯により、ファイルは単なる変換表によって直ちにテキストとして読めるテキストファイルと、それ以外のバイナリファイルに区別される。
テキストファイルでは、たとえば1byteを1文字に変換するような変換表を用意することで、bit列を文字として扱うことができる。このとき、変換する文字の集合を符号化文字集合と呼び、特定の変換表に従って文字とbit列を対応させる(これを符号化と呼ぶ)方式を文字符号化方式、あるいは文字コードと呼ぶ。文字コードにはASCIIやUTF-8などがあるが、英数字に関してはASCIIが一般的であり、他の文字コードでも英数字はASCIIと同じコードを割り当てることが多い。ASCIIコードの例を表1に示す。ASCIIコードでは、1つの文字を7bitで符号化している。
| 文字 | コード | |
|---|---|---|
| 10進 | 16進 | |
| SP | 32 | 20 |
| ! | 33 | 21 |
| " | 34 | 22 |
| # | 35 | 23 |
| $ | 36 | 24 |
| % | 37 | 25 |
| & | 38 | 26 |
| ' | 39 | 27 |
| ( | 40 | 28 |
| ) | 41 | 29 |
| * | 42 | 2a |
| + | 43 | 2b |
| , | 44 | 2c |
| - | 45 | 2d |
| @ | 64 | 40 |
| A | 65 | 41 |
| B | 66 | 42 |
| C | 67 | 43 |
| D | 68 | 44 |
| E | 69 | 45 |
2.2 ファイルの圧縮
大抵のデータファイルには、同じ並びのbit列が何度も現れる事が多い(このような状態を冗長性が高いという)。テキストファイルに関して言えば、同じ単語やフレーズが何回も登場する小説のようなものを考えると良い。このようなファイルに対しては、重複する単語をより短いビット列に置き換えることで、ファイルの容量を少なくすることができる。さらに圧縮率を高めるために、高頻度で登場する情報(文字等)には少ないビット数、頻度が低い情報には多いビット数を割り当てる、符号化を行うなどの工夫がある。
このように、ファイルの容量を小さいサイズに変換することを「ファイルの圧縮」と呼ぶ。また、圧縮されたファイルを元に戻すことを解凍や展開と呼ぶ。圧縮の方法には様々なアルゴリズムが提案されており、DEFLATEアルゴリズムを使ったZip形式が広く使われている。
一方で、音声や画像、動画などのマルチメディアコンテンツを扱うファイルは、テキストファイルに比べ、ファイルサイズが巨大化しやすいため、初めから圧縮方式を取り入れたフォーマットとなっている場合がある。画像ファイルにおいては、BMP形式は非圧縮でデータを保存しているが、PNG形式は圧縮処理を行っているため同じ内容にもかかわらず、ファイルサイズは非常に小さくなっている。このような既に圧縮された冗長性の低いファイル類をさらに圧縮しても、ファイルサイズはほとんど変化しない。
2.3 ハフマン符号
ハフマン符号は広く知られた圧縮手法である。データのうち、多く出現するものには短い符号長の記号、あまり出現しないものには長い符号長の符号を割り当てることで、全体としてデータサイズを少なくすることが可能になる。具体例として、A~Eのアルファベットに可変長で符号を割り当てることを考える。A~Eまでの文字が全てで30文字あり、表2の頻度で存在しているとすると、出現頻度をもとに、図1のような木構造を作ることで符号を割り当てることができる。このような木をハフマン木と呼ぶ。これらを頻度の少ない順に並べ、2つを結合し、再び少ない順に並べることを繰り返すことで、ハフマン木を生成することができる。この結果、各文字に割り当てられた符号は表2のようになる。ハフマン符号による符号化では文字の登場頻度により木の形が変わるので、符号割り当て表がなければ元の文字に戻すことができない。
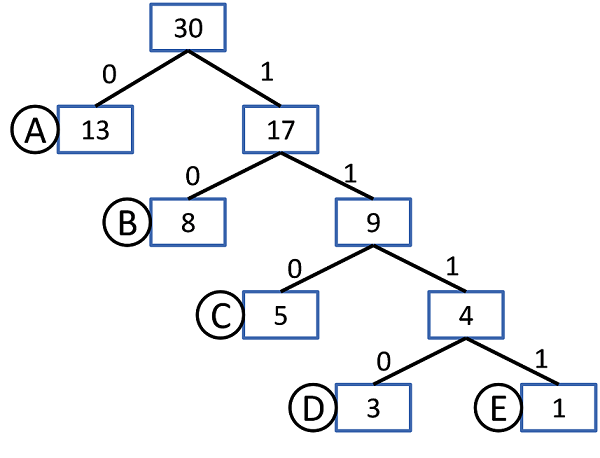
| 文字 | 頻度 | 符号 |
|---|---|---|
| A | 13 | 0 |
| B | 8 | 10 |
| C | 5 | 110 |
| D | 3 | 1110 |
| E | 1 | 1111 |
3. 実験方法
実験書では手順を丁寧に説明しているため、実験方法が非常に長くなっている。レポートに書く際は、実験を再現できる必要最低限の情報のみ記述すること。
3.1 サーバーへの接続
Azure 上のサーバーに ssh にて接続する。サーバーの情報については実験中に説明する。
3.2 データの準備
サーバ上で、mkdirコマンドで作業用ディレクトリを作成する。
mkdir binary
サーバ上のディレクトリ/home/ohashiにある、workdata.zipを作業用ディレクトリにコピーする。
cp /home/ohashi/workdata.zip binary/
Tip
Azure上でなく、自前のMacやLinux上で作業を行う場合、
curl -O https://www.gifu-nct.ac.jp/elec/ohashi/jikken/workdata.zip
でworkdata.zipをダウンロードしてください。
作業用ディレクトリ内のファイルを表示すると、workdata.zipがコピーされていることを確認できる。
cd binary
ls
workdata.zipをunzipコマンドで解凍する。
unzip workdata.zip
ディレクトリ内のファイルを表示すると、
ls
workdataというディレクトリができた。
このディレクトリに移動する。
cd workdata
再度ディレクトリ内のファイルを表示すると、
ls -l
以下のような表示が出てくる。(学生によって多少文字が違う)
total 908
-rw-r--r-- 1 xxx student 805558 May 10 2023 alice2.bmp
-rw-r--r-- 1 xxx student 20779 May 10 2023 alice3.png
-rw-r--r-- 1 xxx student 36842 May 10 2023 huffman.jar
-rw-r--r-- 1 xxx student 50801 May 10 2023 pg108-p.txt
ディレクトリ内に4つのファイルがあることがわかる。
lsに-lオプションをつけると、ファイルサイズを確認することができる。
たとえば
-rw-r--r-- 1 xxx student 50801 May 10 2023 pg108-p.txt
の場合、ファイルサイズは50801バイトである。
- ls [options]... [file]...
- List information about the FILEs.
- options:
-a: do not ignore entries starting with-l: use a long listing format.- cd [directory]
- Change the working directory.
Tip
現在のディレクトリは./、親ディレクトリは../と指定する。
3.3 バイナリエディタによるファイルの確認
テキストファイルpg108-p.txt
をxxdコマンドで開くことで、ファイルを16進で表示できる。
xxd pg108-p.txt
- xxd [options] [infile]
- make a hexdump
- options:
-b: Switch to bits (binary digits) dump, rather than hexdump.
また、ASCII コードの場合は文字列と解釈した結果が右側に表示される。表示の例を図2に示す。
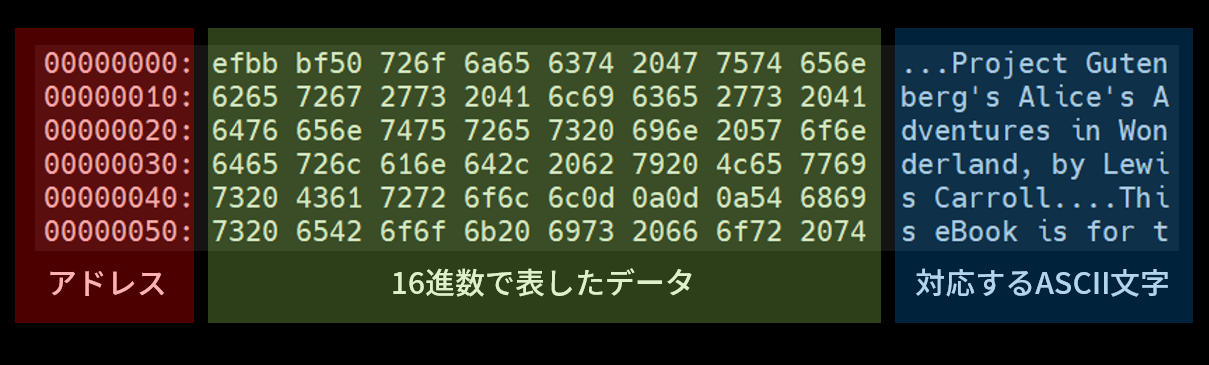
左側のアドレスを見ると、下1桁がすべて0になっていが、これは実際にアドレスが10刻みになっているわけではない。
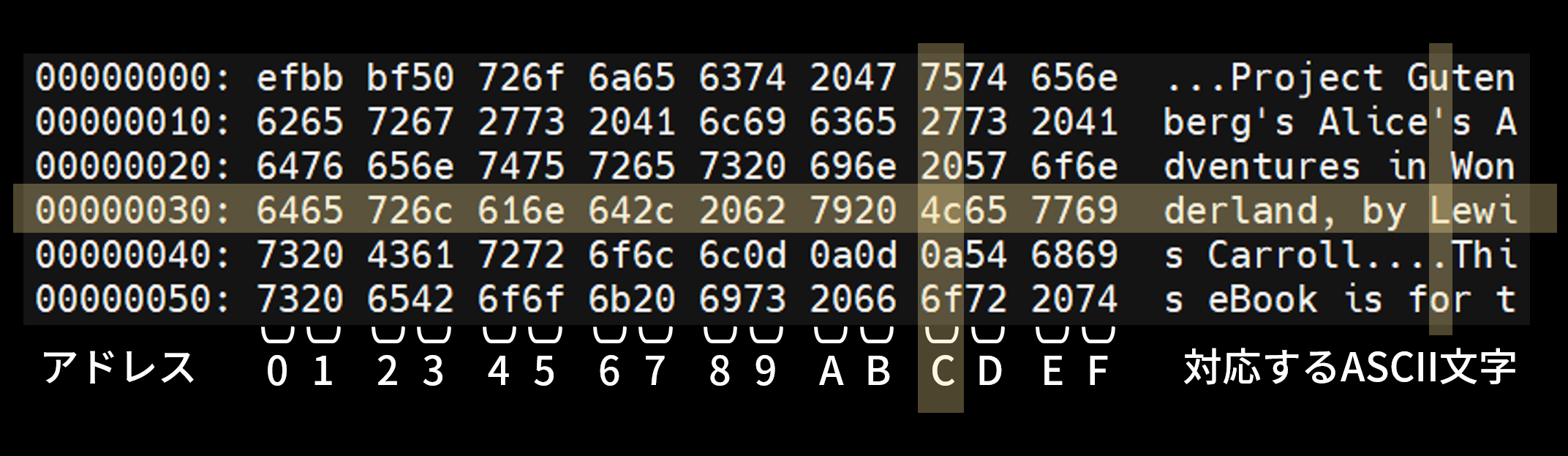
1バイト、つまり16進数の2桁ぶんで1つのアドレスがついているため、アドレスの下1桁は図3のように求められる。
図3では例としてアドレス0000003Cのデータを取り出している。下1桁のCに対応する2桁の16進数と、ASCII文字を取り出している。
各ファイルをバイナリエディタで開き、指定したアドレスにあるデータの 16 進数を調べ、表3を埋めよ。
ただし、pg108-p.txtについては、各16進数をASCII文字として解釈した結果をあわせて記入せよ。
alice2.bmpについては、各16進数を色として解釈した結果をあわせて記入せよ。00は黒、ffは白を意味する。それ以外のデータが出てきた場合には、ヘッダ情報など画素以外のデータである可能性がある。
alice3.pngでは文字や色を記入する必要はない。
| ファイル名 | 種類 | アドレス | 16進数 | 文字(色) |
|---|---|---|---|---|
| pg108-p.txt | テキスト | 0000 003C | ||
| 0000 0265 | ||||
| 0000 02DF | ||||
| 0000 02E1 | ||||
| alice2.bmp | バイナリ | 0000 003C | ||
| 0000 0935 | ||||
| 0005 EB3F | ||||
| alice3.png | バイナリ | 0000 003C | ||
| 0000 07F0 | ||||
| 0000 253E |
3.4 ファイルのアーカイブと圧縮/解凍オプション
tar コマンドを利用し、ファイルのアーカイブと圧縮/解凍を行う。
tar コマンドでは複数ファイルやディレクトリのアーカイブを行うことができる。
先の3つのファイルをそれぞれ、gzip, bzip2, xz
の3種類の形式で圧縮する。アーカイブの拡張子はそれぞれ.tar.gz, .tar.bz2,
.tar.xz
となる。これらのファイルサイズを調査する。ファイルサイズは1バイト単位まで正確に調べて、結果を表4にまとめる。また、3つのファイルをまとめて圧縮した場合についても同様に調査する。
まずは、pg108-p.txtをgzipで圧縮し、pg108-p.txt.tar.gzというファイルを作成する。
tar -cvzf pg108-p.txt.tar.gz pg108-p.txt
次に、pg108-p.txtをbzip2で圧縮し、pg108-p.txt.tar.bz2というファイルを作成する。
オプションのzをjに変更し、出力ファイル名の拡張子も.tar.gzから.tar.bz2に変更する。
tar -cvjf pg108-p.txt.tar.bz2 pg108-p.txt
次に、pg108-p.txtをxzで圧縮し、pg108-p.txt.tar.xzというファイルを作成する。
オプションのjをJに変更し、出力ファイル名の拡張子も.tar.bz2から.tar.xzに変更する。
tar -cvJf pg108-p.txt.tar.xz pg108-p.txt
ここまで終了したら、
ls -l
で作成したファイルを確認すると、以下のように表示される。
total 684
-rw-r--r-- 1 xxx xx 50801 Apr 10 2020 pg108-p.txt
-rw-r--r-- 1 xxx xx Apr 13 09:15 pg108-p.txt.tar.bz2
-rw-r--r-- 1 xxx xx Apr 13 09:15 pg108-p.txt.tar.gz
-rw-r--r-- 1 xxx xx Apr 13 09:15 pg108-p.txt.tar.xz
-rw-r--r-- 1 xxx xx 805558 Apr 10 2020 alice2.bmp
-rw-r--r-- 1 xxx xx 20779 Apr 10 2020 alice3.png
-rw-r--r-- 1 xxx xx 36842 May 11 2017 huffman.jar
(一部を空欄にしています)
もとのファイルpg108-p.txtのファイルサイズと、アーカイブしたファイルのサイズを表4に記録する。
同様の操作をalice2.bmpとalice3.pngにも行う。なお、ファイルの種類によっては、圧縮するとファイルサイズが大きくなる場合がある。
最後に、3つをまとめて圧縮した場合のファイルサイズを調査する。
無圧縮の場合のファイルサイズは、もとの3つのファイルサイズを合計すればよい。
pg108-p.txtとalice2.bmpとalice3.pngをまとめてgzipとして圧縮するには、以下のように入力ファイルを列記する。
tar -cvzf aliceall.txt.tar.gz pg108-p.txt alice2.bmp alice3.png
bzip2, xzでも同様の操作を行い、ファイルサイズを記録する。
- tar -c [-f ARCHIVE] [OPTIONS] [FILE...]
- store multiple files in a single file (an archive), and manipulate such archives.
- options:
-c: Create a new archive. Arguments supply the names of the files to be archived.-v: Verbosely list files processed.-f: Use archive file. If it is set, its value will be used as the archive name.-z: Filter the archive through gzip.-j: Filter the archive through bzip2.-J: Filter the archive through xz.-x: Extract files from an archive.
| ファイル名 | 種類 | 圧縮方式 | サイズ(byte) | 圧縮率 |
|---|---|---|---|---|
| pg108-p.txt | テキスト | 非圧縮 | 1.00 | |
| gzip | ||||
| bzip2 | ||||
| xz | ||||
| alice2.bmp | バイナリ | 非圧縮 | 1.00 | |
| gzip | ||||
| bzip2 | ||||
| xz | ||||
| alice3.png | バイナリ | 非圧縮 | 1.00 | |
| gzip | ||||
| bzip2 | ||||
| xz | ||||
| 3つをまとめて圧縮 | 混合 | 非圧縮 | 1.00 | |
| gzip | ||||
| bzip2 | ||||
| xz |
3.5 ハフマン符号によるファイルの圧縮
ハフマン符号用の符号化プログラムhuffman.jarプログラムを実行して、入力ファイルにpg108-p.txtを指定する。
java -jar huffman.jar
- java -jar file.jar
- The java tool launches a Java application.
少し待つと、図4のような画面が表示される。この画面で、入力ファイルの「参照」をクリックする。
図5のように、今回作業しているディレクトリbinaryディレクトリの中の、workdataディレクトリの中の、pg108-p.txtを指定してopenする。
図6のように出力ファイルを参照し、同じディレクトリにalphabet1というファイル名でsaveする。
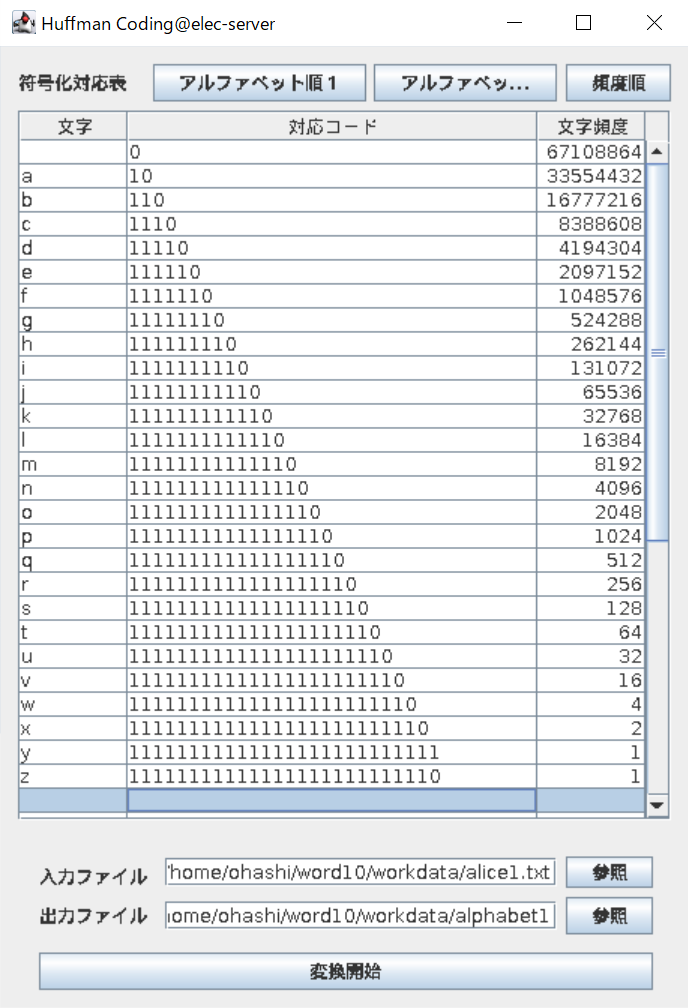
アルファベット順1をクリックすると図7のように文字と2進数の対応表が出てくる。この変換表をスクリーンショットなどで保存してから、変換開始をクリックする。
アルファベット順2についても同様に、出力ファイルを参照してalphabet2というファイル名でsaveし、アルファベット順2をクリックして表のスクリーンショットを撮ってから変換開始する。
頻度順についても同様に、出力ファイルを参照してhindoというファイル名でsaveし、頻度順をクリックして表のスクリーンショットを撮ってから変換開始する。
符号化したファイルをxxdコマンドで 16 進数もしくは 2
進数表示して、符号化が正しく行われているか確認する。全ては大変なので、一つのファイルに対して、先頭の4文字ぶん確認する。図8のようにまとめると良い。

ls -lで各ファイルサイズを確認する。ここでは必要なぶんだけ掲載する。
-rw-r--r-- 1 xxx xx 50801 Apr 10 2020 pg108-p.txt
-rw-r--r-- 1 xxx xx Apr 13 09:42 alphabet1
-rw-r--r-- 1 xxx xx Apr 13 09:43 alphabet2
-rw-r--r-- 1 xxx xx Apr 13 09:43 hindo
(一部を空欄にしています)
ここからファイルサイズと、各符号化方法での1文字あたりのビット数を計算する。
もとのファイルpg108-p.txtでは、1文字が1バイトだった。ヘッダ情報がないとすると、バイト数がそのまま文字数だと考えられる。
alphabet1、alphabet2、hindoでは文字数はもとのpg108-p.txtと変わっていないため、ここから1文字あたりのビット数を求めることができる。
3.6 文字のカウント(発展課題)
この課題は、時間が余ったときのみ行えばよい。
実験3.5で「頻度順」で符号化するためには、各文字の出現頻度をカウントする必要がある。
3.5ではプログラムの中で自動的にカウントされたが、このカウントが正しいかを確かめる。
このためにはいくつかの方法がある。以下に2つの方法を紹介する。
シェル
たとえばaの個数を数えたい場合、以下のように記述すればよい。
grep -o -i a pg108-p.txt | wc -l
同様に、bの個数を数えたい場合、以下のように記述すればよい。
grep -o -i b pg108-p.txt | wc -l
- grep [OPTION...] PATTERNS [FILE...]
- search a file for a pattern
- options:
-o: Print only the matched (non-empty) parts of a matching line, with each such part on a separate output line.-i: Ignore case distinctions in patterns and input data, so that characters that differ only in case match each other. (※caseとは大文字小文字のこと)- wc [OPTION]... [FILE]...
- Print newline, word, and byte counts for each FILE, and a total line if more than one FILE is specified. A word is a non-zero-length sequence of characters delimited by white space.
- options:
-l: print the newline counts
コマンド中の|はパイプと呼び、左のコマンドの出力を右のコマンドの入力にする。
つまり、最初のコマンドであれば、grepコマンドでaの個数分だけa1文字の行が出力される。この結果をwcコマンドの入力とし、行数をかぞえることでaの個数を出力している。
参考:mebee.info/2020/05/10/post-9301
Python
Pythonプログラムを組んでカウントする場合、標準ライブラリのcollectionsからCounter()を使うと便利である。
note.nkmk.me/python-collections-counter
4. 検討課題
- 3つのファイルをまとめて圧縮した場合と、それぞれを圧縮した結果の和が一致しない理由について考察せよ。
- 可変長の符号化と固定長の符号化それぞれの利点、欠点についてまとめよ。
参考文献
Ubuntu manuals accessed on 10.13.2021