データサイエンス演習
はじめに
この実験では2人1組で行う。
1週目は以下の4+1テーマから指定された1テーマについて演習する。
2週目は自分が行った演習に基づき、独自の解析を行って発表する。
発表に使うデータは演習で使ったものを推奨するが、意欲があれば他のデータでも構わない。
1. 実験の目的
実際のデータを使ってデータ解析を行うことで、データから適切な手法で知見を引き出し考察する技術を身につける。
2. 実験の理論
2.1 データ解析
近年ではIoT技術の発展やコンピュータの性能向上、社会の情報化などにより、多くのデータが様々な組織に蓄積されている。こうしたデータに対して演算や可視化などの処理を行い、新たな知見を得ることをデータ解析という。データをそのままの形で見るのではなく、適切な処理を行ってグラフなどに可視化することで、有益な発見が得られることがある。
2.2 オープンデータ
デジタル庁オープンデータ基本指針には以下のように記述がある。
「国、地方公共団体及び事業者が保有する官民データのうち、国民誰もがインターネット等を通じて容易に利用(加工、編集、再配布等)できるよう、次のいずれの項目にも該当する形で公開されたデータをオープンデータと定義する。
- 営利目的、非営利目的を問わず二次利用可能なルールが適用されたもの
- 機械判読に適したもの
- 無償で利用できるもの[1]」
これらのデータはデータの収集主体でない個人でもデータ解析に活用できる。
オープンデータは様々な形式で配布されているが、そのうち代表的なものを紹介する。
(1) Web API
ある機能を実行するプログラムから見て、外部のプログラムがその機能を利用しやすいよう、HTTPプロトコルを用いてネットワーク越しに呼び出すアプリケーション間のインターフェースをWeb API (Web Application Programming Interface)と呼ぶ。
APIは、その内部構造がわからなくても機能と呼び出し方さえわかれば機能が使えるメリットがある。
データを提供するためのWeb APIでは、HTTPリクエストで指定されたデータを返す。この際のデータ形式にはJSONが使われることが多い。
(2) CSVファイルでの配布
一部のWebサイトでは、データをCSVファイルで配布している。
2.3 相関
一方の変数が増加するともう一方の変数が増加あるいは減少するような、2つの変数間の直線的な関係性のことを相関関係という。この関係性の強さを定量的に表す指標が相関係数である。相関係数は-1から1までで表され、値がマイナスであれば負の相関、プラスであれば正の相関がある。
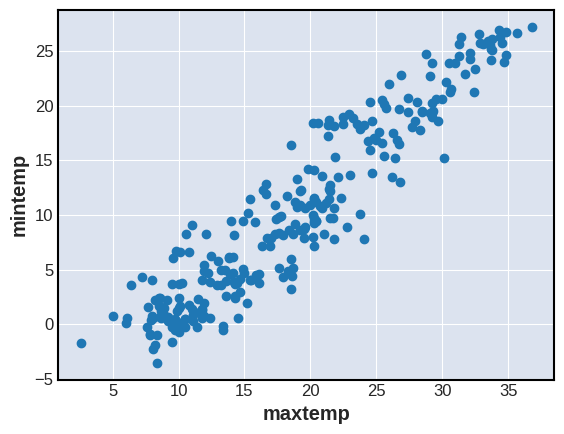
たとえば、東京の2022-04-24から過去1年間の各日最高気温を横軸、最低気温を縦軸に散布図を描いたものが図1である。最高気温が高いほど最低気温が高い傾向があり、強い正の相関が見て取れる。この2変数の相関係数は0.94である。
2020年3月から8月までの日本での各日の公共交通機関訪問者数の相対的な割合を横軸、家にいた平均的な時間の割合を縦軸にとった散布図が図2である。公共交通機関の訪問者が多いほど家にいる時間が短いことが見て取れるが、このように一方の変数がが高いほど他方の変数が低い相関を負の相関という。この2変数の相関係数は-0.85である。
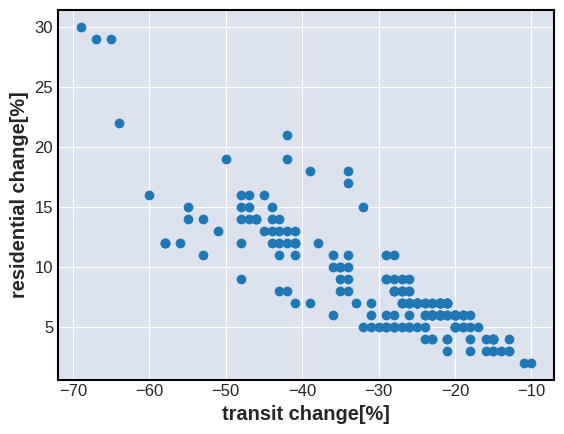
図3は2022-04-24から過去270日間に日本語版Googleで"Python"というワードで検索された回数の指標を横軸、"コロナ"が検索された回数の指標を縦軸にした散布図である。この2つにはほとんど関係性がなく、相関がないといえる。この2変数の相関係数は0.029である。

相関係数 は以下の式で求められる。
はデータ個数、 はそれぞれのデータ、 はそれぞれ の平均である。
2.4 単回帰分析
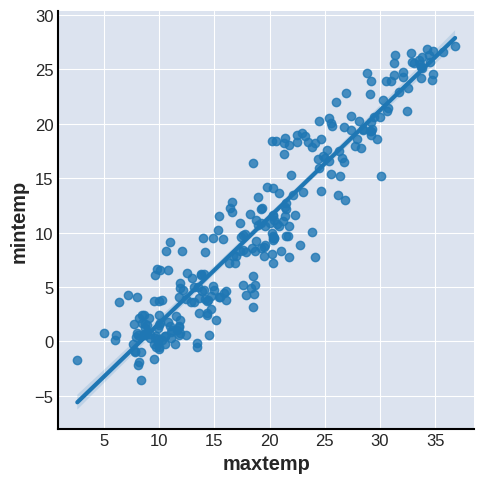
一方の変数(説明変数)の値だけをもとに、もう一方の変数(目的変数)の値を直線的に予測する分析を単回帰分析という。図1の2変数に対して単回帰分析を行って求めた結果をもとに引いた線を追加したものが図4である。実験結果の整理に用いる最小二乗法と同様に、ばらついた点の中心を通るような1次方程式を得ることができる。
データ から単回帰式 の (切片)、 (回帰係数)は以下のように求められる。 はそれぞれ の平均である。
単回帰分析では、切片と回帰係数の他に決定係数が求められる。決定係数は回帰式へのデータの当てはまりの良さを示す。1に近いほどデータが回帰式に当てはまっている。
2.5 データ解析の流れ
今回のデータ解析では、以下のような手順で解析を行うとよい。実際に社会で活用されるデータ解析では解決したい課題が決まっていたり、データ取得から行うことも多いため、やや異なる手順を取る場合もある。
(1) 検証したい事象を考える
今回のデータ解析では使うデータを予め指定しているが、それらのデータを使ってどのようなことを定量的に検証可能かを考える。
今回用いるのは相関関係の分析と単回帰分析のため、「このデータとこのデータにはどのくらい関係性があるか?それはどのような関係性か?」という視点で考えるとよい。意欲のある学生は他の解析を行ってもよい。
(2) 仮説を立てる
検証したい事象について、自らの知識と経験をもとに検証結果の仮説を立てる。仮説を立てた理由についても説明できるようにする。
(3) データを集める
検証したい仮説に合ったデータを選択し、取得する。
(4) データを解析する
検証したい仮説に合った解析方法でデータを解析する。
(5) 結果を解釈する
解析結果をもとに、仮説が正しいかどうかを検討する。
2.6 pandasライブラリ
今回の実験では、分析するデータを保管するのに便利なpandasライブラリを使う。
使い方の説明は以下にある。
7-1. pandasライブラリ — 東京大学 Pythonプログラミング入門
3. 実験方法
以下に指定するデータを取得し、相関関係の解析と、単回帰分析を行う。データの中には、パラメータなどを変更すると取得できる結果を変更できるものもある。まずは指定されたデータで解析し、そのあと発表のために独自にデータを取得して解析してもよい。
A Google検索数とコロナ感染者
「抗原検査」のGoogle検索数と国内コロナ感染者との関係について、第6波のデータを解析する。
B 仮想通貨と株価指数
仮想通貨イーサリアムの価格とアメリカの株価指数S&P500との関係について解析する。
C google検索数とWikipediaアクセス数
「高専」のGoogle検索数と「高等専門学校」のWikipediaアクセス数の関係について解析する。
D 気温とGoogle検索数
「鍋」のGoogle検索数と東京の最高気温との関係について解析する。
E 為替の解析
ドル円と日米の金利差の関係について解析する。
※このテーマはある程度の金融知識が必要となる。
4. 発表課題
発表は1組あたり8分(発表パート5分、議論パート3分)で行う。仮説とその検証結果についてプレゼンにまとめること。議論を起こすようなオリジナリティのある発表が望ましい。
議論パートでは、発表を聞いている学生からの質問や意見を発端にして、学生による主体的な議論を期待する。発言中の学生を遮らなければ自由な発言を許可するが、挙手をしている学生がいる場合そちらを優先する。活発な議論を行った学生には、発表の評価に加点する。
発表は教員が採点する。採点基準は以下の通りである。
| 配点 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|
| 内容 | 仮説があり、十分な検証が実施されている | 仮説があり、検証が実施されている | 仮説があり、少し検証が実施されている | 仮説があるが検証が不十分 | 仮説しかない |
| スライド | 誰もが見て内容がわかるようなスライドになっている | 説明があれば、内容がわかるようなスライドになっている | 十分な説明があれば、内容がわかるスライドになっている | 説明があっても、わからない箇所が少しある | 説明があっても、わからない箇所が多数ある |
これに加え、以下の項目で加減点を行う。
| 加減点項目 | 点数 |
|---|---|
| 活発に議論に参加していた | +1点 |
| 発表パートが20秒以上早く終了した | -2点 |
| 発表パートが10秒以上遅く終了した | -2点 |
| 発表でグループ内での発言数が極端に偏っている | -2点 |
5. レポート課題
通常のレポートと同様の様式を用い、表紙を除き2~4ページとする。記述する項目は以下のようにする。
1. 解析の目的
事象の検証について、なぜそれを検証したいのか述べる。
2. 仮説
事象について立てた仮説と、その仮説を立てた理由を述べる。
3. 解析方法
解析の方法を他の人がある程度再現できるように述べる。
4. 解析結果
解析結果を述べる。仮説とも比較する。
5. 考察
解析結果と仮説を比較し考察する。追加の解析が必要であれば行う。
参考文献
[1] デジタル庁オープンデータ基本指針 accessed on 2022/04/26